最近写论文笔记是各种疯(捉)狂(襟)百(见)度(肘)啊,对于自身的技术能力个人感觉实在是“太下饭”了。算算从五月份自学到现在也半年有余,买过书上过课,从最开始接触 Andrew Ng 的 Coursera上的机器学习课程到入手第一本西瓜书之后,又陆陆续续买了《机器学习实战》、《统计学习方法(第2版)》、《百面机器学习》等等,其实我的想法是很简单,跟着书后面死磕,总会培养出感情,无奈这几个月非但没看得到进步,反而越发觉得这门技术并非单单凭兴趣就能攻克的,它所需要的知识脉络是全面的,容不得一丝侥幸,因此既然这样,干脆来个二次入门。再加上临近年末也需要个人总结一下这一年的得与失,是时候给自己立个FLAG。
这次死磕系列结合《统计学习方法》,这本书涵盖了机器学习领域涉及到的各种核心技术研究,包括自然语言处理、信息检索、文本数据挖掘等。我也会尝试融合西瓜书一起,从零开始,做到手推算法重理解,尽量直观展示备注说明,并在每章最后附上经典面试题,或者是一个案例实战(数据竞赛题之类),以期可以系统性的掌握一套方法论应对未来数据之战。
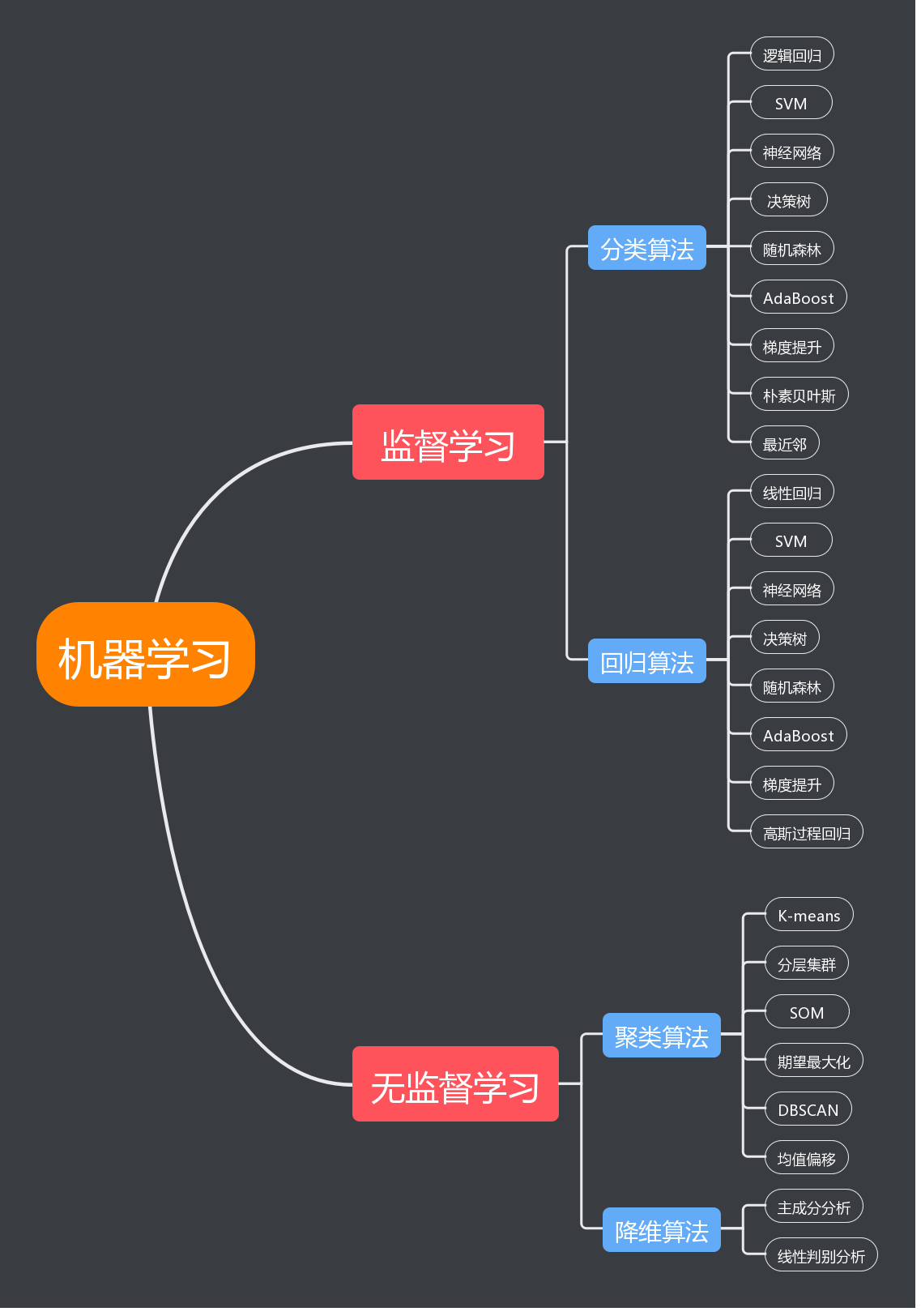
系列目录如下
继《统计学习方法》一书之后,接下来着手的是有着“AI圣经”之称的《模式识别和机器学习》,业界普遍称其为PRML,相信任何一个搞机器学习、深度学习的人都应该听说过甚至看过,它共有14章节的内容,且每一章都是干货满满。整体目录如下:
系列目录如下
第一章 介绍
第二章 概率分布
第三章 线性回归模型
第四章 线性分类模型
第五章 神经网络
第六章 内核方法:双重表征、构造内核、径向基函数网络、高斯过程
第七章 稀疏内核机器:最大边距分类器、相关向量机
第八章 图形模型:贝叶斯网络、条件独立、马尔科夫随机场、图形模型中的推理
第九章 混合模型和EM:K-means聚类、高斯混合、EM算法
第十章 近似推断
第十一章 采样方法
第十二章 连续潜在变量
第十三章 顺序数据
第十四章 组合模型
更令人兴奋地是,目前PRML已经被微软“开源”啦
传送门
附上学习路线图