对于NLP领域来说,稍微拿一块知识点出来研究都是别有洞天,此篇是贪心学院布置的第一篇论文Lecture,于2015年由华盛顿大学发表,主要是为计算文本(语句)相似度提出的一种度量方法。在此之前,计算两个文档的相似度主要是通过词频,但这其实很难作为衡量依据的。
因此这篇论文的意义在于它提出这样一种思想:通过使用词向量(Word2Vec)表示词语,用WMD(Word Mover’s Distance)来衡量向量距离,以此计算文档相似度。
通过简单用例来阐述可能会更好,如下:
- A - “编程 使 我 快乐”
- B - “唱歌 使 我 快乐”
- C - “我 觉得 编程 有乐趣 “
统计得到词袋向量:
- A - [“编程”:$\frac{1}{4}$,”使”:$\frac{1}{4}$,”我”:$\frac{1}{4}$,”快乐”:$\frac{1}{4}$,”唱歌:0,”觉得”:0,”有乐趣”:0]
- B - [“编程”:0,”使”:$\frac{1}{4}$,”我”:$\frac{1}{4}$,”快乐”:$\frac{1}{4}$,”唱歌:$\frac{1}{4}$,”觉得”:0,”有乐趣”:0]
- B - [“编程”:$\frac{1}{4}$,”使”:0,”我”:$\frac{1}{4}$,”快乐”:0,”唱歌:0,”觉得”:$\frac{1}{4}$,”有乐趣”:$\frac{1}{4}$]
通过以上的特征向量,可以很明显看出第一句和第二句相似度很高,但是从我想要表达的语义来看,第一句和第三局似乎内容更匹配更有串联关系。再比如经典等式:king-man = queen-women,因此通过词频(IF-TDF)表示法是比较难表达语句中丰富的语义信息。这也正是这篇论文的意义所在,其核心思想在于突出词与词之间的距离特征映射关系。
简介
本文主要是提出一种基于词移动距离(Word Mover’s Distance, WMD)的文本相似度计算方法。它把大量的工作都用在了word2vec训练词向量(围绕基于词在句子中的总共出现概率训练词向量来展开的),WMD距离计算是针对某篇文章中的每一个词的,并在对比文档中找到一个词,使得该词“travel”到原文档中词的“cost”最小(即两个词向量最小距离),因而两篇文章相似度其实就是一篇文章中的所有词转移到另一篇文章中的词的”总代价“。这里得提一下EMD(下文有介绍 点击跳转),WMD和EMD两者的思路其实是一样的。这种衡量方法最直接的好处在于计算从头至尾都没有用到超参数,而且在paper中也论证了WMD的简单可效,在当时WMD算法甚至击败了其他7种主流文本相似度度量算法,具体可查看论文Figure 3柱状图了解。
有关研究工作
Word2Vec Embedding(词向量嵌入)
Word2vec 维基百科是这样解释的:它是一群用来产生词向量的相关模型。这些模型为浅两层的神经网络,用来训练以此重新构建符合语言学下的词文本。所以它也是一种词向量的表示模型,经过转换,可以把原先稀疏的特征转化为稠密的特征,而且语义相近的词之间的欧式距离也会比语义无关的词距离更大,这就相当于根据语义把意思相似的词聚合在很近的空间范围之内。
关于Word2Vec感觉还能再细分下去,后面抽时间再整理一下。
Earth Mover’s Distance(推土机距离)
EMD距离用来表示两个分布的相似程度,它是归一化的从一个分布变为另一个分布的最小代价,虽然其主要应用在图像处理和语音信号处理领域里,但是在NLP里似乎也深受其影响,因为这很符合文本对比的特点:两个文本里面包含的词语肯定不可能一致,所以也就肯定能够找到这样一个代价使得文本之间的相似性度量达到最大,这也正是下面要介绍的WMD算法。
Word Mover’s Distance(词移距离)
再看上面的用例,计算转移距离的时候,为了得到最小的距离,A中的”编程/我”,会全部转移到C中的”编程/我”(距离代价为0),而”快乐/有乐趣”以及”觉得/使”也是最接近的,也全部转移。因此,从本质上来说,在计算语句相似度时,WMD算法会计算文章中最相近的词之间的距离,但不会考虑整体,这大大增加的算法的健壮,不会因为文章整体的异同而表现出算法的不顽健。
先理解一下WMD算法:
1)有 词向量矩阵,其中n是数据集大小,d是词向量维度
2)某篇文章表示成归一化后的词袋向量为
3)那么每一维度就是该词在文章出现的次数,很显然这个BOW是非常稀疏的,因为大量的词是不会出现在同一篇文章里的(TF-IDF,能出现大概率的只会是无语义词)
4)当两篇文章都用词袋向量表示后,如果语义相近,且用词也相近就可以知道向量的距离肯定也是相近的。但是如果两篇文章语义相近但是用词不同,那么这俩个向量的距离就会很散。
5) word2vec计算两篇文章中的两个词的距离向量,记为
6) 定义转移矩阵,其中:矩阵中的每一个值代表单词i有多少权重要flow到单词j,我们只需保证,该词flow出的权重等于该单词在BOW中所有的权重即可,即。
7) 只需找到累加求和距离最小权重分配比, 就可以求出最终两文本间的相似度。
最终数学表达公式为:
s.t:
附上图
图一: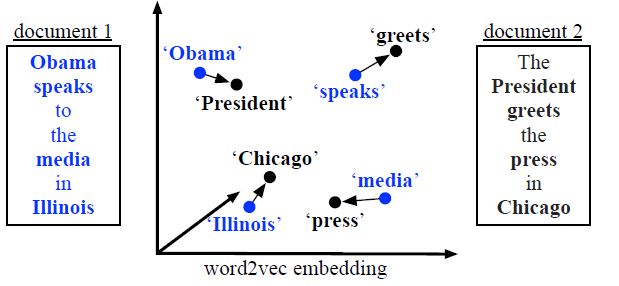
图一说明单词移动距离。两篇文档中所有不间断的单词(粗体)都嵌入到另一个word2vec空间中
图二:
(上)WMD度量组件在查询语句及语句,(两者有相等的词袋模型距离)间的展示。箭头表示两个单词之间的流动,并标有它们的距离贡献。
(下)两个语句和之间的流动情况展示,这种不匹配是由WMD将单词移动到了多个相似的单词导致的。
总结
到这里,简单描述了整篇论文的核心算法思想,当然还有很多研究工作需要进行,包括对WMD算法的优化之类,本文主要是为后续的文本相似度计算打下点基础,在熬了三周后参考各种文档,有关文本相似度计算总算是入门了,既然选择这一行,再难都会过去,就跟当初毕业走上Android开发这条路一样,学就对了。
这里可参考词移距离gensim官方Demo,这是一款主题模型开源库。


