对于NLP领域来说,稍微拿一块知识点出来研究都是别有洞天,此篇是贪心学院布置的第一篇论文Lecture,于2015年由华盛顿大学发表,主要是为计算文本(语句)相似度提出的一种度量方法。在此之前,计算两个文档的相似度主要是通过词频,但这其实很难作为衡量依据的。
因此这篇论文的意义在于它提出这样一种思想:通过使用词向量(Word2Vec)表示词语,用WMD(Word Mover’s Distance)来衡量向量距离,以此计算文档相似度。
通过简单用例来阐述可能会更好,如下:
- A - “编程 使 我 快乐”
- B - “唱歌 使 我 快乐”
- C - “我 觉得 编程 有乐趣 “
统计得到词袋向量:
- A - [“编程”:$\frac{1}{4}$,”使”:$\frac{1}{4}$,”我”:$\frac{1}{4}$,”快乐”:$\frac{1}{4}$,”唱歌:0,”觉得”:0,”有乐趣”:0]
- B - [“编程”:0,”使”:$\frac{1}{4}$,”我”:$\frac{1}{4}$,”快乐”:$\frac{1}{4}$,”唱歌:$\frac{1}{4}$,”觉得”:0,”有乐趣”:0]
- B - [“编程”:$\frac{1}{4}$,”使”:0,”我”:$\frac{1}{4}$,”快乐”:0,”唱歌:0,”觉得”:$\frac{1}{4}$,”有乐趣”:$\frac{1}{4}$]
通过以上的特征向量,可以很明显看出第一句和第二句相似度很高,但是从我想要表达的语义来看,第一句和第三局似乎内容更匹配更有串联关系。再比如经典等式:king-man = queen-women,因此通过词频(IF-TDF)表示法是比较难表达语句中丰富的语义信息。这也正是这篇论文的意义所在,其核心思想在于突出词与词之间的距离特征映射关系。
简介
本文主要是提出一种基于词移动距离(Word Mover’s Distance, WMD)的文本相似度计算方法。它把大量的工作都用在了word2vec训练词向量(围绕基于词在句子中的总共出现概率训练词向量来展开的),WMD距离计算是针对某篇文章中的每一个词的,并在对比文档中找到一个词,使得该词”travel”到原文档中词的”cost”最小(即两个词向量最小距离),因而两篇文章相似度其实就是一篇文章中的所有词转移到另一篇文章中的词的”总代价”。这里得提一下EMD(下文有介绍 点击跳转),WMD和EMD两者的思路其实是一样的。这种衡量方法最直接的好处在于计算从头至尾都没有用到超参数,而且在paper中也论证了WMD的简单可效,在当时WMD算法甚至击败了其他7种主流文本相似度度量算法,具体可查看论文Figure 3柱状图了解。
有关研究工作
Word2Vec Embedding(词向量嵌入)
Word2vec 维基百科是这样解释的:它是一群用来产生词向量的相关模型。这些模型为浅两层的神经网络,用来训练以此重新构建符合语言学下的词文本。所以它也是一种词向量的表示模型,经过转换,可以把原先稀疏的特征转化为稠密的特征,而且语义相近的词之间的欧式距离也会比语义无关的词距离更大,这就相当于根据语义把意思相似的词聚合在很近的空间范围之内。
关于Word2Vec感觉还能再细分下去,后面抽时间再整理一下。
Word2Vec 架构详解:CBOW vs Skip-gram
Word2Vec由Mikolov等人于2013年提出,包含两种互补的架构:
CBOW(Continuous Bag-of-Words,连续词袋模型):
- 思想:用上下文(周围词)预测中心词
- 输入:窗口内上下文词的one-hot向量(或求和后的向量)
- 输出:中心词的概率分布
- 目标函数:最大化 $\log P(w_t | w_{t-k}, …, w_{t-1}, w_{t+1}, …, w_{t+k})$
- 优点:训练速度快(每个样本只做一次前向传播就能得到所有上下文词的梯度),对高频词效果好
- 缺点:对罕见词的表征能力不如Skip-gram
Skip-gram:
- 思想:用中心词预测周围的上下文词
- 输入:中心词的one-hot向量
- 输出:窗口内每个位置上下文词的概率分布
- 目标函数:最大化 $\sum_{-k \leq j \leq k, j \neq 0} \log P(w_{t+j} | w_t)$
- 优点:对罕见词的表征质量更高(每个中心词产生多个训练样本),是WMD论文中使用的架构
- 缺点:训练速度比CBOW慢
关键选择:WMD论文使用的是Skip-gram模型,因为Skip-gram对低频词的表示质量更好,而WMD算法的计算质量高度依赖于每个词向量的语义准确性。
训练加速技巧
当词汇表大小达到百万级别($|V| \approx 10^6$),标准softmax每次计算需要遍历整个词汇表求和,成本 $O(|V|)$ 在训练中是不可接受的。Word2Vec使用两种加速策略:
Hierarchical Softmax(层次Softmax):
- 将词汇表构建成一棵哈夫曼树(Huffman Tree),叶子节点为词,内部节点为逻辑回归二分类器
- 高频词靠近根节点,编码路径短;低频词在深层,编码路径长
- 每次预测只需计算从根到目标词叶子节点路径上 $O(\log |V|)$ 个二分类器
- 总训练复杂度从 $O(|V|)$ 降至 $O(\log |V|)$
Negative Sampling(负采样):
- 将多分类问题转化为二分类问题:给定一个(中心词,上下文词)对,判断它是真实共现还是随机噪声
- 目标函数:$\log \sigma(v_{w_O}^T v_{w_I}) + \sum_{i=1}^{k} \mathbb{E}{w_i \sim P_n(w)}[\log \sigma(-v{w_i}^T v_{w_I})]$
- 其中 $k$ 是负样本数(通常 $k = 5 \sim 20$),$P_n(w)$ 是噪声分布(通常为词频的 $3/4$ 次幂)
- 每次训练只需更新 1 个正样本 + $k$ 个负样本的词向量,复杂度 $O(k)$
- 负采样在实践中最常用(gensim 的默认选项),训练速度和词向量质量均优于层次softmax
Word2Vec 训练流程
- 语料预处理:分词、去停用词、低频词过滤(通常
min_count=5)、子采样高频词(subsampling,以概率 $P(w_i) = 1 - \sqrt{t / f(w_i)}$ 丢弃,$t \approx 10^{-5}$) - 构建训练样本:滑动窗口(通常
window=5)生成(中心词,上下文词)对 - 随机初始化:为每个词初始化两个向量——输入向量 $v_w$ 和输出向量 $u_w$(维度通常 $d = 100 \sim 300$)
- 随机梯度下降:使用负采样或层次softmax计算梯度并更新
- 最终词向量:通常取输入向量 $v_w$ 作为最终词向量;也可取 $v_w + u_w$ 或两者的拼接
此时,每个词被表示为一个 $d$ 维稠密向量,且语义相近的词在向量空间中距离相近(如 $\vec{v}(\text{king}) - \vec{v}(\text{man}) + \vec{v}(\text{woman}) \approx \vec{v}(\text{queen})$)。
Earth Mover’s Distance(推土机距离)
EMD距离用来表示两个分布的相似程度,它是归一化的从一个分布变为另一个分布的最小代价,虽然其主要应用在图像处理和语音信号处理领域里,但是在NLP里似乎也深受其影响,因为这很符合文本对比的特点:两个文本里面包含的词语肯定不可能一致,所以也就肯定能够找到这样一个代价使得文本之间的相似性度量达到最大,这也正是下面要介绍的WMD算法。
EMD 的正式数学定义
EMD(Earth Mover’s Distance)是衡量两个概率分布之间差异的最优传输(Optimal Transport)度量。其正式定义如下:
问题设定:给定两个分布的签名(Signatures):
- 源分布 $P = {(p_1, w_{p1}), …, (p_m, w_{pm})}$,其中 $p_i$ 是位置,$w_{pi}$ 是权重
- 目标分布 $Q = {(q_1, w_{q1}), …, (q_n, w_{qn})}$,其中 $q_j$ 是位置,$w_{qj}$ 是权重
定义地面距离矩阵 $\mathbf{D} \in \mathbb{R}^{m \times n}$,其中 $d_{ij}$ 是从位置 $p_i$ 到 $q_j$ 的”运输成本”。
EMD 的线性规划形式:
$$EMD(P, Q) = \min_{\mathbf{T} \geq 0} \frac{\sum_{i=1}^{m}\sum_{j=1}^{n} T_{ij} d_{ij}}{\sum_{i=1}^{m}\sum_{j=1}^{n} T_{ij}}$$
$$\text{s.t. } \sum_{j=1}^{n} T_{ij} \leq w_{pi}, \quad \forall i \in \{1,...,m\}$$
$$\sum_{i=1}^{m} T_{ij} \leq w_{qj}, \quad \forall j \in \{1,...,n\}$$
$$\sum_{i=1}^{m}\sum_{j=1}^{n} T_{ij} = \min\left(\sum_{i} w_{pi}, \sum_{j} w_{qj}\right)$$
其中 $\mathbf{T}$ 是传输矩阵,$T_{ij}$ 表示从源 $i$ 传送到目标 $j$ 的量。分母是归一化因子,使得EMD的结果度量两个分布形状的差异而非总量差异。
最优传输理论与 Kantorovich-Rubinstein 对偶
EMD是Monge-Kantorovich最优传输问题的特例。Monge原始问题(1781)要求找到一个一一映射将源分布的质量推到目标分布,而Kantorovich放宽了这个要求:允许多对多的质量拆分与合并。
Kantorovich-Rubinstein 对偶性给出EMD的等价形式:
$$EMD(P, Q) = \sup_{\|f\|_L \leq 1} \left(\int f dP - \int f dQ\right)$$
其中 $|f|_L$ 表示函数 $f$ 的Lipschitz常数。这揭示了EMD作为积分概率度量(Integral Probability Metric)的本质。
与 Wasserstein 距离的关系
在数学中,EMD等价于1-Wasserstein距离($W_1$):
$$W_p(P, Q) = \left(\inf_{\gamma \in \Gamma(P,Q)} \mathbb{E}_{(x,y) \sim \gamma}[\|x - y\|^p]\right)^{1/p}$$
当 $p=1$ 时即为EMD。Wasserstein距离是比KL散度和JS散度”更平滑”的分布距离度量,即使两个分布的支撑集不重叠也能提供有意义的梯度——这对GAN训练(WGAN)至关重要。WMD正是将这一理论引入NLP领域计算文档相似度。
Word Mover’s Distance(词移距离)
再看上面的用例,计算转移距离的时候,为了得到最小的距离,A中的”编程/我”,会全部转移到C中的”编程/我”(距离代价为0),而”快乐/有乐趣”以及”觉得/使”也是最接近的,也全部转移。因此,从本质上来说,在计算语句相似度时,WMD算法会计算文章中最相近的词之间的距离,但不会考虑整体,这大大增加的算法的健壮,不会因为文章整体的异同而表现出算法的不顽健。
先理解一下WMD算法:
1)有 词向量矩阵$$\mathbf{X}\in \mathbf{R}^{d*n}$$,其中n是数据集大小,d是词向量维度
2)某篇文章表示成归一化后的词袋向量为$$\mathbf{b}\in \mathbf{R}^{n}$$
3)那么每一维度就是该词在文章出现的次数,很显然这个BOW是非常稀疏的,因为大量的词是不会出现在同一篇文章里的(TF-IDF,能出现大概率的只会是无语义词)
4)当两篇文章都用词袋向量$$\mathbf{b}$$表示后,如果语义相近,且用词也相近就可以知道向量的距离肯定也是相近的。但是如果两篇文章语义相近但是用词不同,那么这俩个向量的距离就会很散。
5) word2vec计算两篇文章中的两个词的距离向量,记为$$\mathbf{c}(i,j)$$
6) 定义转移矩阵$$\mathbf{T}\in \mathbf{R}^{n*n}$$,其中:矩阵中的每一个值$$T_{i,j}$$代表单词i有多少权重要flow到单词j,我们只需保证,该词flow出的权重等于该单词在BOW中所有的权重即可,即$$\sum_{j}^{}\mathbf{T}_{ij}=d_j$$。
7) 只需找到累加求和距离最小权重分配比, 就可以求出最终两文本间的相似度。
最终数学表达公式为:
$$min\sum_{i,j=1}^{n}\mathbf{T}_{ij} \mathbf{c}(i,j)$$
s.t: $$\sum_{j=1}^{n}\mathbf{T}_{ij}=d_i$$ $$\forall _i\in \{1,...,n\}$$ $$\cdots \cdots \cdots (1) $$
$$\sum_{i=1}^{n}\mathbf{T}_{ij}=d'_j$$ $$\forall _j\in \{1,...,n\}$$
附上图
图一: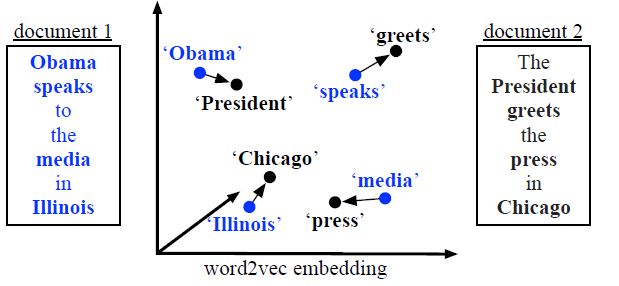
图一说明单词移动距离。两篇文档中所有不间断的单词(粗体)都嵌入到另一个word2vec空间中
图二:
(上)WMD度量组件在查询语句$$D_0$$及语句$$D_1$$,$$D_2$$(两者有相等的词袋模型距离)间的展示。箭头表示两个单词之间的流动,并标有它们的距离贡献。
(下)两个语句$$D_3$$和$$D_0$$之间的流动情况展示,这种不匹配是由WMD将单词移动到了多个相似的单词导致的。
WMD 算法详细解析(Algorithm in Detail)
问题形式化
设两篇文档 $D$ 和 $D’$,词汇表大小为 $n$。每篇文档用归一化词袋向量(nBOW)表示:
$$\mathbf{d} = \left(\frac{c_1}{\sum c_i}, \frac{c_2}{\sum c_i}, ..., \frac{c_n}{\sum c_i}\right)$$
其中 $c_i$ 是词 $i$ 在文档中出现的次数。归一化确保了 $\sum_i d_i = 1$,使得文档被表示为词汇表上的概率分布。
WMD定义为求解以下线性规划问题:
$$\text{WMD}(\mathbf{d}, \mathbf{d}') = \min_{\mathbf{T} \geq 0} \sum_{i,j=1}^{n} T_{ij} \cdot c(i,j)$$
$$\text{s.t. } \sum_{j=1}^{n} T_{ij} = d_i \quad \forall i \in \{1,...,n\}$$
$$\sum_{i=1}^{n} T_{ij} = d'_j \quad \forall j \in \{1,...,n\}$$
其中 $c(i,j) = |\mathbf{x}_i - \mathbf{x}_j|_2$ 是词 $i$ 和词 $j$ 在Word2Vec嵌入空间中的欧氏距离。
算法步骤
Step 1: 词汇表过滤
对于给定的两篇文档,只需要考虑实际出现在至少一篇文档中的词。设两篇文档分别包含 $p$ 和 $q$ 个不同词,则最优传输问题规模缩减为 $p \times q$,而非整个词汇表 $n \times n$。这是WMD实际可行的关键。
Step 2: 构建代价矩阵
计算两篇文档中所有词对之间的欧氏距离,形成 $p \times q$ 的代价矩阵 $\mathbf{C}$:
$$\mathbf{C}_{ij} = \|\mathbf{x}_{i}^{(D)} - \mathbf{x}_{j}^{(D')}\|_2$$
其中 $\mathbf{x}_{i}^{(D)}$ 是文档 $D$ 中第 $i$ 个词的Word2Vec向量。
Step 3: 构建权重向量
将文档中每个词的归一化权重构建为向量 $\mathbf{d} \in \mathbb{R}^p$ 和 $\mathbf{d}’ \in \mathbb{R}^q$。
Step 4: 求解线性规划
求解上述线性规划问题得到最优传输矩阵 $\mathbf{T}^*$。这是一个标准的运输问题(Transportation Problem),可以用网络单纯形法(Network Simplex)或通用LP求解器求解。
伪代码
Algorithm: WMD(D1, D2, word_vectors) |
算法复杂度分析
- 代价矩阵构建:$O(p \cdot q \cdot d)$,其中 $d$ 是词向量维度(通常 $d=300$),$p, q$ 是两篇文档的独特词数
- 线性规划求解:使用网络单纯形法,运输问题的求解复杂度为 $O((p+q)^3 \log(p+q))$。在WMD的典型场景中,通常 $p, q \leq 500$(单篇文档的不同词数),求解仍在可接受范围内
- 总复杂度:$O(p \cdot q \cdot d + (p+q)^3 \log(p+q))$
对于KNN检索场景(给定查询文档 $D_q$,在 $N$ 个文档的语料库中找到最相似的 $k$ 个),朴素方法需要计算 $N$ 次WMD,总复杂度为 $O(N \cdot (p^3 \log p))$,这在 $N$ 较大时不可行。这正是后面要讨论的优化技术所解决的问题。
松弛 WMD(Relaxed WMD, RWMD)
由于精确WMD的计算代价较高(对KNN检索尤为明显),Kusner等人提出了松弛版本RWMD,通过放松一个方向的约束来获取WMD的下界(Lower Bound),可大幅加速检索。
词心距离(Word Centroid Distance, WCD)
如果将文档中所有词的权重集中到它们的质心(加权平均向量),则得到WCD:
$$WCD(\mathbf{d}, \mathbf{d}') = \left\|\sum_i d_i \mathbf{x}_i - \sum_j d'_j \mathbf{x}_j\right\|_2$$
WCD的计算复杂度仅为 $O(p \cdot d)$,是WMD的一个非常松散的下界。它等价于”所有词必须从同一个点出发,运到同一个终点”——这显然不可能比WMD(逐个词灵活匹配)的代价更大。
松弛上界(Relaxed Upper Bound)
放松目标文档的约束(允许目标文档的词被无限量接收),即只保留源文档的质量守恒约束:
$$RWMD_1(\mathbf{d}, \mathbf{d}') = \sum_i d_i \cdot \min_j c(i, j)$$
同理,放松源文档的约束:
$$RWMD_2(\mathbf{d}, \mathbf{d}') = \sum_j d'_j \cdot \min_i c(i, j)$$
这两个松弛版本的计算复杂度均为 $O(p \cdot q \cdot d)$(需要遍历所有词对找最小距离),但可通过预计算近邻索引加速至 $O(p \cdot \log n \cdot d)$。
松弛下界
取两个松弛方向的最大值作为WMD的下界:
$$RWMD(\mathbf{d}, \mathbf{d}') = \max(RWMD_1, RWMD_2)$$
速度-准确率权衡:
| 方法 | 计算复杂度 | 相对误差 | 用途 |
|---|---|---|---|
| WCD | $O(pd)$ | 大(松散下界) | 粗筛 |
| RWMD | $O(pq)$ | 较小(紧下界) | 精筛 |
| WMD | $O(p^3\log p)$ | 零(精确值) | 最终比较 |
RWMD的实际价值巨大:对于 $N=10^4$ 级别的语料库,纯WMD的KNN检索需要数小时,而RWMD可以在秒级完成筛选,再用WMD精确计算Top-K候选文档。
WMD 与传统文本相似度度量对比
详细对比表
| 度量方法 | 数学基础 | 考虑词序 | 考虑语义 | 处理未登录词 | 计算复杂度 | 适用场景 |
|---|---|---|---|---|---|---|
| WMD | 最优传输 + Word2Vec | 否 | 是 | 忽略未知词 | $O(p^3\log p)$ | 短文本、文档检索 |
| Cosine (TF-IDF) | 向量空间模型 | 否 | 否 | 忽略 | $O(p)$ | 长文档、信息检索 |
| Jaccard | 集合论 | 否 | 否 | 忽略 | $O(p)$ | 快速去重 |
| LDA / Topic Model | 概率图模型 | 否 | 部分(主题级) | 忽略 | $O(Kp)$ | 主题聚类 |
| Doc2Vec | 段落向量 | 部分(上下文窗口) | 是 | 忽略 | $O(d)$ | 长文档分类 |
| BERT / Sentence-BERT | Transformer + 预训练 | 是(位置编码) | 是 | 子词切分缓解 | $O(L^2)$ | 所有场景(最优但最贵) |
| BLEU / ROUGE | n-gram 重叠 | 是(n-gram) | 否 | 0分 | $O(p)$ | 机器翻译/摘要评估 |
各方法详解
余弦相似度 + TF-IDF:最经典的方法。将文档映射为 TF-IDF 加权向量,计算余弦相似度。优点:极快、可解释。缺点:完全忽视词义——“car”和”automobile”的贡献为零。
Jaccard 相似度:两文档共有词数除以两文档总词数。仅适用于精确去重场景,语义能力为零。
LDA(Latent Dirichlet Allocation):将文档表示为主题分布,然后计算分布相似度。在主题粒度上有一定语义能力,但远不如WMD的逐词语义匹配粒度细。
Doc2Vec(Paragraph Vector):学习文档的稠密向量表示,然后计算余弦相似度。有一定语义能力,但需要大量标注/无监督数据训练,且对短文本效果不佳。
BERT / Sentence-BERT:最现代的方法。BERT通过多层Transformer捕获上下文信息,Sentence-BERT通过孪生网络微调更适合相似度判断。优点:全面。缺点:推理成本高,单句推理需约 $10^7 \sim 10^8$ 次浮点运算(WMD仅需查表+欧氏距离)。
WMD 的优势场景
WMD在无超参数、不需额外训练、可解释性好、对短文本友好方面具有独特优势。它不需要像BERT那样庞大的GPU集群做推理,也不像TF-IDF那样对同义词束手无策。对于那些”需要一定语义理解但又没有训练数据和GPU预算”的场景,WMD是很好的折中方案。
优化技术(Optimization Techniques for WMD)
精确WMD的LP求解在KNN检索中不可接受。论文和后续研究提出了多种加速策略:
Prefetch and Prune(预取与剪枝)
这是Kusner等人在原论文中提出的核心优化:
- 第一阶段(Prefetch):对所有候选文档计算WCD($O(Npd)$),按WCD升序排列
- 第二阶段(Prune):从WCD最小的文档开始,计算RWMD。如果某文档的RWMD下界已经大于当前已知的Top-K最大WMD值,则跳过该文档及所有WCD更大的文档(因为WCD $\leq$ RWMD $\leq$ WMD)
- 第三阶段(Verify):对通过剪枝的候选文档,计算精确WMD作为最终排序依据
这个策略可以剪枝掉 90% 以上的候选文档,将KNN检索的实际耗时降至近似 $O(N \cdot pq)$ 级别。
NNDescent 加速
NNDescent(Dong et al., 2011)是一种基于近邻图的精确kNN加速方法,可应用于WMD场景:
- 构建KNN图(每个文档的近似K近邻)
- 通过邻居的邻居迭代优化KNN图(”朋友的朋友可能是朋友”)
- 在KNN图上做局部精确WMD计算
NNDescent通常只需要数十次迭代即可逼近真实KNN,实践中可以将 $N=10^6$ 级的KNN检索时间从”数天”降至”数小时”级别。
预计算词最近邻
对于RWMD中的 $\min_j c(i,j)$ 查找,可以预计算每个词在整个词汇表中的Top-$M$ 最近邻(如 $M=100$),存储为查找表。查询时只需要检查 $M$ 个候选而非整个词汇表,将 $O(pq)$ 降至 $O(p \cdot M)$。这是”以空间换时间”的经典策略。
更快的LP求解器
标准LP求解器对于运输问题并非最优。使用专用算法可进一步提升:
- Sinkhorn算法:通过熵正则化将原始LP松弛为可迭代求解的矩阵缩放问题,每次迭代只需矩阵乘法,GPU友好。复杂度 $O(pq \cdot t)$($t$ 为迭代次数,通常 $t \approx 20 \sim 50$)
- 不完全Cholesky分解:利用核矩阵的低秩近似加速
这些方法在近似WMD(允许小误差)的场景下特别有效。
Python 实现(Implementation)
以下是使用 gensim 和 pyemd 库计算WMD的完整示例:
import numpy as np |
注意事项
- 分词:中文需要先分词(jieba/pkuseg),英文需要tokenization和去停用词
- OOV(Out of Vocabulary)处理:对于不在词向量表中的词,gensim的
wmdistance会直接忽略(不参与质量和运输)。如果一篇文档的所有词都是OOV,则距离为0(根据gensim实现)或无穷大(我们自己的实现则需显式处理) - 归一化:确保两篇文档的词权重都归一化为概率分布($\sum_i d_i = 1$)
- 库依赖:gensim 的 WMD 依赖 pyemd(通过
pip install pyemd安装);如果没有 pyemd,gensim 会 fallback 到较慢的纯Python实现
应用场景(Applications of WMD)
文档检索(Document Retrieval)
给定查询文档,在语料库中检索Top-K最相似文档。这是WMD最自然的应用。在Kusner论文的实验中,WMD在8个文档分类数据集的KNN检索任务上,错误率比TF-IDF + LDA + SVM等方法降低了最多10个百分点。
文本聚类(Text Clustering)
将WMD作为聚类算法的距离度量,可以产生语义上更一致的聚类结果。常用的方法:
- K-medoids with WMD:使用 $k$-medoids 而非 $k$-means(因为WMD没有显式的向量表示,无法计算”均值”),medoid是到簇内其他点WMD总和最小的文档
- Hierarchical Clustering:使用WMD作为linkage的距离度量
释义检测(Paraphrase Detection)
WMD天然适合判断两句话是否互为释义——因为释义的核心特征是词不同但语义相同。通过WMD将语义相近的词匹配起来,可以有效捕获释义关系。结合适当的距离阈值,可以在Microsoft Paraphrase Corpus等标准数据集上取得良好的效果。
跨语言文档匹配(Cross-lingual Document Matching)
WMD的一个独特优势:如果使用多语言词向量(如MUSE——Multilingual Unsupervised Embeddings),可以将不同语言的文档映射到同一个嵌入空间,然后用WMD进行跨语言相似度计算。这不需要任何平行语料对齐,完全由多语言词向量驱动。
局限性分析(Limitations)
未登录词问题(Out-of-Vocabulary)
WMD的质量完全依赖词向量的覆盖率和质量。对于未登录词,标准做法是直接丢弃——这会导致文档中部分语义信息丢失。可能的缓解策略:
- 使用fastText(子词n-gram)代替Word2Vec,对OOV词用n-gram组合估算向量
- 使用BERT等上下文模型(但代价增大)
计算代价
精确WMD的 $O(p^3\log p)$ 复杂度在以下场景中成为瓶颈:
- 实时查询(要求毫秒级响应)
- 大规模语料库($N > 10^5$)
- 长文档($p > 1000$)
RWMD和剪枝策略缓解了KNN检索场景,但对于实时应用仍需近似方法。
文档长度敏感性
WMD对文档长度比较敏感。长文档包含更多词,理论上可能”稀释”WMD距离。归一化词袋权重解决了统计层面的问题,但无法改变长文档有更多匹配机会的事实。实践中,对于长度差异悬殊的文档对,WMD的区分度会下降。
词序信息丢失
WMD基于词袋表示,完全不考虑词序。这使得它无法区分:
- “狗咬人” vs “人咬狗”(完全相同的词汇分布)
- “not good” vs “good”(否定词位置决定语义)
对于需要精确语义判断的场景(如情感分析、蕴含推理),这是一个重要限制。
词向量质量依赖
WMD的性能上限取决于底层词向量的质量。如果词向量没有正确捕获近义词/反义词关系(如将”good”和”bad”映射得太近),WMD会产生误导性的高相似度分数。此外,静态词向量(Word2Vec/GloVe)无法处理一词多义——“bank”(河岸)和”bank”(银行)有相同向量,但语义完全不同。
现代演进(Modern Evolution)
WMD是静态词向量时代的巅峰之作。随着预训练语言模型的发展,文档相似度领域也经历了重大变革:
BERTScore(Zhang et al., 2020)
BERTScore将WMD的思想迁移到上下文嵌入空间:
- 用BERT代替Word2Vec获取每个token的上下文相关向量
- 对参考文本和候选文本中的每个token做贪心匹配(类似WMD的松弛版本)
- 计算Precision、Recall和F1三个维度的分数
- 不需要额外的训练数据,利用BERT的预训练知识即可
优势:上下文感知(同一个”bank”在不同句子中有不同向量)、处理词序信息、对释义/翻译评估效果好
MoverScore(Zhao et al., 2019)
MoverScore可以看作是”BERT版的WMD”:
- 使用BERT或ELMo的上下文嵌入
- 将WMD的运输框架完整保留
- 在n-gram级别(而非词级别)做运输匹配
- 天然支持多对多对齐(区别于BERTScore的贪心匹配)
优势:保留WMD的多对多运输灵活性,同时受益于上下文嵌入的信息量
Sentence-BERT(Reimers & Gurevych, 2019)
Sentence-BERT(SBERT)走向了另一个方向:直接用孪生网络微调BERT以获得句子级别的向量表示,然后计算余弦相似度。这一范式避开了WMD的LP求解,速度极快(只需单次前向传播即可获得句子向量)。
性能对比(在语义文本相似度STS基准上):
| 方法 | STS-Benchmark Spearman | 推理时间(单对文档) |
|---|---|---|
| WMD + Word2Vec | ~0.65 | ~10ms (小文档) |
| WMD + GloVe | ~0.67 | ~10ms |
| BERTScore | ~0.78 | ~100ms |
| MoverScore | ~0.79 | ~200ms |
| Sentence-BERT (base) | ~0.85 | ~1ms |
从 WMD 到现代方法的技术脉络
WMD的开创性贡献在于提出了”词级别的语义运输”这一思想框架。这个思想在后来的BERTScore和MoverScore中被完美继承——只是将运输的”基础单元”从静态词向量升级为了上下文相关嵌入。可以说,理解WMD是理解现代文档相似度方法的基石。
总结
到这里,简单描述了整篇论文的核心算法思想,当然还有很多研究工作需要进行,包括对WMD算法的优化之类,本文主要是为后续的文本相似度计算打下点基础,在熬了三周后参考各种文档,有关文本相似度计算总算是入门了,既然选择这一行,再难都会过去,就跟当初毕业走上Android开发这条路一样,学就对了。
这里可参考词移距离gensim官方Demo,这是一款主题模型开源库。
最后附上论文链接:http://proceedings.mlr.press/v37/kusnerb15.pdf
面试常见问题(Interview Q&A)
Q1: WMD相比TF-IDF余弦相似度的核心优势是什么?请用数学语言解释。
答:TF-IDF余弦相似度将文档表示为词汇表空间中的稀疏向量,计算的是两个向量夹角的余弦值:$\cos(d_1, d_2) = \frac{d_1 \cdot d_2}{|d_1||d_2|}$。在此框架下,任何两个不同的词都是正交的(内积为0),”汽车”和”轿车”对相似度的贡献与”汽车”和”天气”完全相同——都是零。
WMD通过引入词向量间的欧氏距离作为”地面运输成本”$c(i,j) = |x_i - x_j|_2$,将文档相似度形式化为了最优传输问题。其核心优势在于:即使两篇文档没有共享任何相同词汇(如 one-hot 意义下的内积为零),WMD也能通过语义相近词的匹配(低 $c(i,j)$)给出有意义的非零相似度。这是从”词汇级别匹配”跃升到”语义级别匹配”的本质区别。
Q2: WMD中的线性规划为什么是一个运输问题(Transportation Problem)?它满足运输问题的哪些特征?
答:运输问题是线性规划的一个经典特例,有以下特征:
- 有 $m$ 个供应源和 $n$ 个需求目标
- 每个供应源 $i$ 有固定的供应量 $d_i$
- 每个需求目标 $j$ 有固定的需求量 $d’_j$
- 总的供应量等于总的需求量($\sum_i d_i = \sum_j d’_j$)
- 目标是最小化总运输成本
WMD完美匹配上述所有特征:文档1的每个词权重 $d_i$ 是”供应量”,文档2的每个词权重 $d’_j$ 是”需求量”,词向量间的欧氏距离 $c(i,j)$ 是”运输成本”,总供应量等于总需求量(归功于nBOW归一化,$\sum_i d_i = \sum_j d’_j = 1$)。这确保了运输问题有可行解——最优传输矩阵 $\mathbf{T}$ 的行和等于 $d_i$,列和等于 $d’_j$。
因此WMD可以直接使用运输问题的专用求解器(如网络单纯形法),而非更通用的线性规划求解器。
Q3: 为什么WMD在KNN检索时需要RWMD做剪枝?RWMD为什么是WMD的有效下界?
答:精确WMD对每对文档需要求解一个 $O(p^3\log p)$ 的LP问题。对于 $N$ 个文档的KNN检索,朴素需要求解 $N$ 次WMD,总复杂度不可接受。
RWMD是有效下界的证明:
回顾RWMD的定义:$RWMD_1 = \sum_i d_i \cdot \min_j c(i,j)$。它放松了目标文档的质量守恒约束($\sum_i T_{ij} = d’j$),只保留源文档的约束($\sum_j T{ij} = d_i$)。
对于WMD的任意可行解 $\mathbf{T}$,有:
$$\sum_{i,j} T_{ij} c(i,j) \geq \sum_{i,j} T_{ij} \cdot \min_k c(i,k) = \sum_i \left(\sum_j T_{ij}\right) \cdot \min_k c(i,k) = \sum_i d_i \cdot \min_k c(i,k) = RWMD_1$$
因此 $RWMD_1 \leq WMD$。同理 $RWMD_2 \leq WMD$。取最大值 $RWMD = \max(RWMD_1, RWMD_2)$ 仍是下界。
剪枝逻辑:如果候选文档 $D$ 的 $RWMD$ 已经大于当前 Top-K 中第 $K$ 大的精确 $WMD$ 值,则 $D$ 不可能是Top-K之一(因为它的 WMD 只会更大)。利用这个逻辑,RWMD可以安全地排除绝大多数候选文档。
Q4: WMD如何处理文档长度差异问题?有哪些注意事项?
答:WMD通过nBOW归一化($\sum_i d_i = 1$)使文档长度本身不直接影响距离计算——每篇文档被表示为词汇表上的概率分布。但是长文档仍可能带来间接影响:
更多独特词:长文档包含更多独特词,增加了”匹配机会”。在极端情况下,一篇包含了语料库中所有词的长文档可能与任何查询文档都计算出较低的WMD,因为它总有找到近义词匹配的资源。这不是真正的语义相似,而是一种长度偏差(Length Bias)。
权重稀释:虽然nBOW归一化到概率1,但长文档中每个词的归一化权重更低,这使得大量低权重词的”分散运输”可能不如少量高权重词的”集中运输”更具判别力。
缓解策略:可以使用截断(只保留TF-IDF最高的Top-$M$个词,$M=50 \sim 200$)来平衡文档长度。Kusner论文中验证了在去除停用词后,文档长度差异对WMD的分类性能影响有限。
Q5: Word2Vec的Skip-gram模型为什么比CBOW更适合作为WMD的词向量基础?
答:这个问题涉及Word2Vec训练机制与WMD使用场景的关系。
对罕见词的表征质量:Skip-gram对每个(中心词,上下文词)对独立训练,每个中心词产生多个训练样本(等于窗口大小乘以2)。CBOW每次将多个上下文词平均后预测中心词,低频词在平均过程中的信号被高频词淹没。WMD对低频但语义关键的词(如专有名词、技术术语)的向量质量要求很高——错误向量会导致错误的运输匹配。
向量空间的语义线性性:Skip-gram训练出的向量空间以更好的线性语义关系著称(king - man + woman = queen)。WMD依赖词向量间的欧氏距离进行语义匹配,良好的线性结构意味着更准确的语义距离度量。
实验验证:Kusner论文中使用的就是Skip-gram训练的词向量(Google News, 300维),实验证明这种配置在文档分类KNN任务上显著优于传统方法。
Q6: 如果给WMD算法打分,它在现代NLP工具链中还值得使用吗?什么场景下会优先选择WMD?
答:WMD在现代NLP中的定位是”轻量级语义匹配”方案。与BERT等模型的对比:
- 计算资源有限的场景:WMD不需要GPU,词向量查找 + LP求解在CPU上即可完成,适合嵌入式设备、边缘计算、或没有GPU的服务器。BERT推理通常需要GPU。
- 无需额外训练:WMD是零样本方法(zero-shot),只要有一个好的词向量表即可直接使用。BERTScore需要加载BERT模型(约400MB+),Sentence-BERT还需要微调。
- 可解释性:WMD的运输矩阵 $\mathbf{T}$ 直接告诉你”文档A的哪个词匹配了文档B的哪个词以及运输了多少质量”,这对于需要解释匹配原因的业务场景(如法律文书比对)很有价值。
- 跨语言场景:使用多语言词向量(如fastText多语言模型),WMD可以直接做跨语言文档匹配,无需任何对齐语料。
综合来看:如果你的任务对语义精度要求极高(如语义蕴含、情感推理),应当选择BERT系列模型。如果任务是对语义有一定要求的文档检索/聚类/去重,且计算资源有限或需要快速原型验证,WMD仍然是一个valid的选择。
Q7: 请推导RWMD作为WMD下界的证明过程,并解释为什么松弛版本的解其值一定不大于精确版本?
答:完整的数学证明如下:
设 $WMD^* = \min_{\mathbf{T} \in \Pi(\mathbf{d}, \mathbf{d}’)} \langle \mathbf{T}, \mathbf{C} \rangle$,其中 $\Pi(\mathbf{d}, \mathbf{d}’)$ 是可行传输集合,满足行和与列和约束。
现在定义 $\Pi_1(\mathbf{d}) = {\mathbf{T} \geq 0 : \sum_j T_{ij} = d_i, \forall i}$——这是只保留行和约束(放松列和约束)的可行域。显然 $\Pi(\mathbf{d}, \mathbf{d}’) \subset \Pi_1(\mathbf{d})$。
$$RWMD_1 = \min_{\mathbf{T} \in \Pi_1(\mathbf{d})} \langle \mathbf{T}, \mathbf{C} \rangle \leq \min_{\mathbf{T} \in \Pi(\mathbf{d}, \mathbf{d}')} \langle \mathbf{T}, \mathbf{C} \rangle = WMD^*$$
不等号成立是因为在更大的可行域 $\Pi_1(\mathbf{d})$ 上搜索最小值,必然能找到不大于在受限域 $\Pi(\mathbf{d}, \mathbf{d}’)$ 上搜索到的值。
接下来求 $RWMD_1$ 的闭式解。对于只受行和约束的问题,每一行 $i$ 的解是独立的:选择 $\min_j C_{ij}$ 对应的 $j$,将全部 $d_i$ 运输到该 $j$。因此:
$$RWMD_1 = \sum_i d_i \cdot \min_j C_{ij}$$
同理 $RWMD_2 = \sum_j d’j \cdot \min_i C{ij}$,且取 $RWMD = \max(RWMD_1, RWMD_2) \leq WMD^*$。
这个下界的紧致程度取决于数据的分布。当两篇文档的词高度重叠且语义高度对齐时,RWMD非常接近WMD(因为最优解几乎就是一阶贪心匹配)。当文档词差异较大时,RWMD和WMD的差距也会增大。

