感知是人类的一种本能,更确切的说是一切对外界有意识的动物的本能。它是对外界信息作出察觉、感觉、注意、知觉的一系列过程。因此,『感知机(Perceptron)』即是会感知的机器,它是机器学习中最最基础的模型,我们可以把它叫做人工神经元,是神经网络(深度学习)的起源算法。感知机在上世纪5、60年代,由科学家Frank Rosenblatt在受到其他科学家学术成果启发上而提出发展起来的。
如今,使用人工神经元的模型很常见,在许多有关神经网络的现代工作领域中,使用的主要神经元模型,其中之一的就是**$sigmoid$神经元**,在了解该神经元之前,先把聚焦点放在感知机上吧。
模型引入
感知机作为单层神经网络,其模型引入最初是为解决是否线性可分问题而提出的,一个感知机接收若干个二进制流输入,经过隐藏层的处理,最后产生一个二进制的输出。大致如下所示:
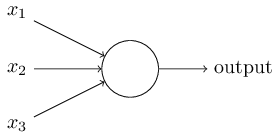
上图所示的感知机有三个输入,当然这个输入是任意的。Rosenblatt在这个模型上提出了一个条简单计算法则来计算输出值。即引入权重。通过权重来表示各自的输入对输出的重要程度。神经元输出值是二进制的,因此只会返回 0 或者 1 ,它的取值是由输入值加权和是否小于或者大于某个阈值来决定的。表示如下:
$output = \left{\begin{matrix}0
& if \sum_{j}w_jx_j \leq threshold
\1
& if \sum_{j}w_jx_j > threshold
\end{matrix}\right.$
以上就是感知机的基本数学模型。也可以这样理解,感知机就是一个通过权衡证据来做决定的机器。这里举一个简单的例子。假设周末你所在的城市即将举行环市马拉松比赛。你是马拉松热爱者,正在决定是否周末参加比赛。
于是你可以通过以下三个因素来决定是否参加:
1、周末我是否有空?
2、周末天气好不好?
3、有朋友跟我一起参加么?
在不考虑权重情况下,我们有这三个输入变量,分别为
$x_1 = { 有空:1; 没空:0 }$
$x_2 = { 天气好:1; 天气坏:0 }$
$x_3 = { 有朋友:1; 没朋友:0 }$
现在假设,即使没有朋友去参加也不怎么影响你去参加马拉松(只因你是狂热爱好者),那么分配给第三个因素权重 $w_3$ = 2,但是如果天气不好,连活动是否举办都受影响的话,就很无奈了,所以这里分配第二个因素权重 $w_2$ = 6,然后对于周末有没有空,除去工作突遇重大安排都能抽出时间参加,给予权重 $w_1$ = 2 影响也不是很大。最后,假设感知器的阈值为5.通过这些选择,感知机实现了所需的决策模型,天气好的时候输出为1,天气不好输出为0。无论是否有朋友一起参加,或者周末有其他事情安排,输出结果都一样,只会跟天气有关。(注:1 * 6 + 0 * 4 恒大于5)
通过改变权重和阈值,我们可以得到很多不同的决策模型。比如我们的阈值设为3,那么感知机就会做出只有天气好的时候你才可以去参加马拉松,或者当有朋友一起参加,并且周末也有空,那么就会去参加比赛。也就是说,这其实是另一种决策模式了。降低阈值,意味着降低了参加马拉松比赛的阻拦因素了。
显然,感知机并不是人类做出决策的一个完整模型。只是这个例子解释了感知机是如何通过权衡不同类型的证据来做出决定的。而一个复杂的感知器网络可以做出非常微妙的决定。见下图:
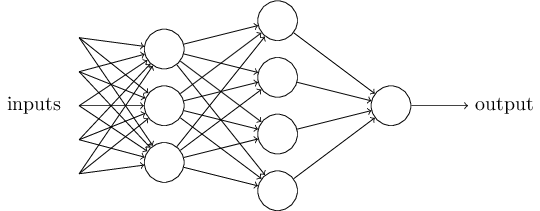
在这个网络中,感知机的第一层 —— 通过权衡输入的证据,做出三个非常简单的决定。那么第二层的感知器呢?每一个感知器都是通过权衡第一层决策的结果来做决定的。这样,第二层的感知器可以在比第一层感知器更复杂、更抽象的层次上做出决定。第三层的感知器甚至可以做出更复杂的决定,依次递进,这样一个多层感知器网络就可以进行复杂的决策程序了。
顺便说一下,当定义感知机时,我们说过的感知机只有一个输出。但在上面这样的感知器网络里,似乎有多个输出。实际上,这些仍然可以看做是单个输出。多个输出箭头仅仅是一种看起来比较分明的方式,用它来指示一个感知器的输出被用作其他几个感知器的输入。它比仅仅画一条输出线然后分割来的更为方便。
接下来简化一下描述感知机的方式,条件 $\sum_{j} w_jx_j > threshold$ 看起来比较繁琐,我们可以通过两个符号变化来简化它。第一个变化,使用点积来表示加权和 $\vec{w}⋅\vec{x} ≡ \sum_{j} w_jx_j$,$\vec{w}$ 和 $\vec{x}$分别表示权重向量的分量和输入;第二个变化是将阈值移到不等式的另一边,并将其替换为所谓的感知器偏差 $b ≡ 阈值$。也就是使用偏差而不是阈值。因此,感知机规则重写如下:
$output = \left{\begin{matrix}0
& if \vec{w}⋅\vec{x} + b \leq 0
\1
& if \vec{w}⋅\vec{x} + b > 0
\end{matrix}\right.$
很显然,对于一个有很大偏差的感知器,感知器越容易输出1,因此我们可以把偏差看作是感知器输出1的容易程度的度量。但其实偏差就是用来衡量感知器触发的难易程度的,但如果偏差非常小,可以想象,感知器就很难输出1。引入偏差只是我们描述感知机的一个小变化,后面也不再使用阈值来描述了,将直接使用偏差。
上面我们一直将感知机描述为一种衡量证据以做出决定的方法。但其实它还有另一种用法,即我们可以使用感知机来计算我们通常认为是基础计算的基本逻辑函数,比如 与门(AND)、或门(OR)、与非门(AND NAND)。例如,假设我们有一个有两个输入的感知机,每个输入的权值均为-2,总体偏差为3,这时我们的感知机:
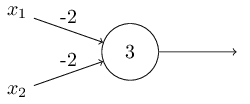
然后我们看到当输入00时,输出值为1(注:(−2) ∗ 0 + (−2) ∗ 0 + 3 = 3 > 0),类似的输入01和10产生的输出值同样是1,但是当输入11,却生成了0,如果对二进制计算熟悉的话,就能很明显的看出这实现了一个与非门(NAND)计算。
NAND的例子表明我们可以使用感知器来计算简单的逻辑函数。事实上,我们可以使用感知器网络来计算任何逻辑函数。因为NAND门对于计算来说是通用的,也就是说,我们可以用与非门构建任何计算。例如,我们可以使用NAND门来构建一个两位元($x_1$ 和 $x_2$)相加的电路,这就需要计算位和,即 $x_1⊕x_2$,以及一个进位,当 $x_1$ 和 $x_2$ 都是1时,进位为1,也即进位就是按位积 $x_1·x_2$,见下图:
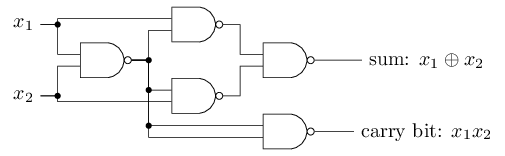
为了得到一个等效的感知机网络,我们将所有的NAND门替换为感知机的两个输入,每个输入的权值均设为-2,总体偏差为3。下图是最终的网络:
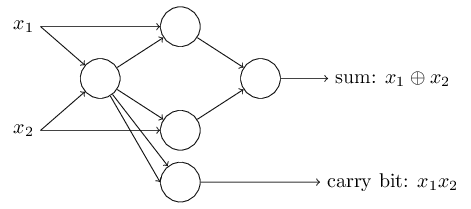
这个感知器网络一个值得注意的方面是,最左边的感知器的输出被用在了最下面感知器的两次输入了。当定义感知器模型时,我们并没有规定这种双输出到同一个地方是违规的。实际上,这并不重要。如果我们不希望出现这种情况,那么可以简单的将这两条线合并成一条,并将其权重由-2改成-4(这里是否等价可以尝试证明一下),而有了这个变化,现在网络看起来如下(注:未标记的权重均为-2,所有的偏差都等于3):
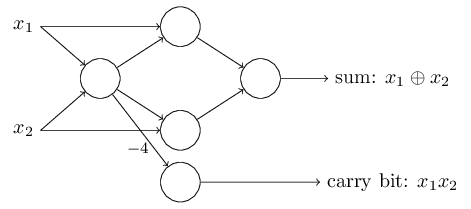
到目前为止,我一直把像 $x_1$ 和 $x_2$ 这样的输入当作浮动在感知器网络左侧的变量。事实上,传统的做法是绘制一个额外的感知器层 —— 输入层 —— 来编码输入:
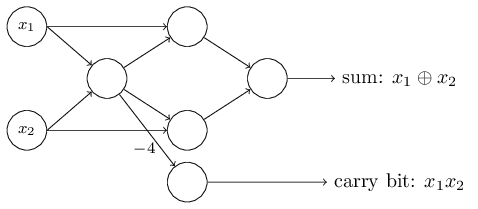
这个符号表示输入感知机,我们有输出,但是没有输入,
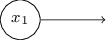
这是一种速记法,但并不意味着这是一个没有输入的感知器。假设我们有一个没有输入的感知器,那么,$\sum_{j} w_jx_j$ 的加权和就会始终为0。因此,如果 $b > 0$,感知器输出1;反之输出0。也就是说,感知器只输出一个固定的值,而不是期望的值($x_1$)。所以最好的理解就是把输入的感知机想成根本不是感知机,而是一些特殊的单位,它们被简单地定义为想要输出的值,
$x_1, x_2, \cdots$
一、感知机的数学形式
1.1 定义
感知机(perceptron)是二类分类的线性分类模型,属于判别模型。其输入为实例的特征向量,输出为实例的类别,取值为 $+1$ 和 $-1$。
从输入空间到输出空间的函数为:
$$ f(x) = \text{sign}(w \cdot x + b) $$
其中:
- $w \in \mathbb{R}^n$:权值向量(weight vector)
- $b \in \mathbb{R}$:偏置(bias)
- $w \cdot x$:权值向量和特征向量的内积
- $\text{sign}$ 是符号函数:
$$ \text{sign}(z) = \begin{cases} +1 & \text{if } z \geq 0 \\ -1 & \text{if } z < 0 \end{cases} $$
1.2 几何解释
在特征空间 $\mathbb{R}^n$ 中,方程 $w \cdot x + b = 0$ 定义了一个超平面(hyperplane),它将特征空间划分为两个半空间:
- 超平面法向量为 $w$
- $w$ 指向的一侧为正类($+1$)
- 背向的一侧为负类($-1$)
- $-\frac{b}{|w|}$ 是原点到超平面的距离
1.3 数据集线性可分
如果存在某个超平面 $w \cdot x + b = 0$ 能够将数据集的正实例和负实例完全正确地分开,则称该数据集为线性可分数据集(linearly separable data set)。感知机算法只能处理线性可分的数据。
二、感知机学习策略
2.1 损失函数的推导
感知机的学习目标:找到一个超平面,能正确划分所有训练样本。
自然的想法是:最小化误分类点的总数。但这个损失函数不是 $w$ 和 $b$ 的连续可导函数,不便于优化。
因此,感知机采用另一种损失函数:误分类点到超平面的总距离。
对于任意一点 $x_i$,它到超平面的距离为:
$$ d_i = \frac{1}{\|w\|} |w \cdot x_i + b| $$
对于误分类点 $(x_i, y_i)$,有:
$$ -y_i (w \cdot x_i + b) > 0 $$
这是因为:
- 如果 $y_i = +1$ 但 $w \cdot x_i + b < 0$(被误分为负),则 $-y_i(w \cdot x_i + b) = -(w \cdot x_i + b) > 0$
- 如果 $y_i = -1$ 但 $w \cdot x_i + b \geq 0$(被误分为正),则 $-y_i(w \cdot x_i + b) = +(w \cdot x_i + b) > 0$
因此,误分类点 $x_i$ 到超平面的距离可以统一写为:
$$ -\frac{1}{\|w\|} y_i (w \cdot x_i + b) $$
忽略常数 $\frac{1}{|w|}$(它不影响梯度下降的方向),感知机的损失函数定义为:
$$ L(w, b) = -\sum_{x_i \in M} y_i (w \cdot x_i + b) $$
其中 $M$ 是所有误分类点的集合。
2.2 损失函数的性质
- 非负性:$L(w, b) \geq 0$(因为对误分类点,$-y_i(w \cdot x_i + b) > 0$)
- 正确分类时为零:没有误分类点时,$M = \emptyset$,$L(w, b) = 0$
- 连续可导:$L(w, b)$ 关于 $w$ 和 $b$ 是连续可导的
三、感知机学习算法:随机梯度下降(SGD)
3.1 梯度计算
损失函数 $L(w, b)$ 关于 $w$ 和 $b$ 的梯度为:
$$
\nabla_w L(w, b) = -\sum_{x_i \in M} y_i x_i
$$
$$
\nabla_b L(w, b) = -\sum_{x_i \in M} y_i
$$
3.2 算法流程
感知机学习算法采用随机梯度下降法(Stochastic Gradient Descent, SGD):每次随机选取一个误分类点进行更新,而非使用全部误分类点。
算法:感知机学习算法的原始形式
输入:训练集 T = {(x_1, y_1), ..., (x_N, y_N)},学习率 η ∈ (0, 1] |
3.3 更新规则的直观理解
当一个点被误分类时(实际为正但被分为负,或实际为负但被分为正),权重更新:
$$ w \leftarrow w + \eta \cdot y_i \cdot x_i $$
几何上:
- 若 $y_i = +1$,更新使 $w$ 向 $x_i$ 方向移动——使超平面转向以正确分类 $x_i$
- 若 $y_i = -1$,更新使 $w$ 背离 $x_i$ 方向移动
3.4 从零实现
import numpy as np |
四、Novikoff 定理:收敛性证明
4.1 定理陈述
Novikoff 定理:设训练数据集 $T = {(x_1, y_1), \dots, (x_N, y_N)}$ 是线性可分的,其中 $x_i \in \mathbb{R}^n$,$y_i \in {-1, +1}$。则:
存在满足 $|\hat{w}{\text{opt}}| = 1$ 的超平面 $\hat{w}{\text{opt}} \cdot \hat{x} = 0$ 将数据集完全正确分开,且存在 $\gamma > 0$,对所有 $i$ 有:
$$ y_i (\hat{w}_{\text{opt}} \cdot \hat{x}_i) \geq \gamma $$令 $R = \max_i |\hat{x}_i|$,则感知机学习算法在训练集上的误分类次数 $k$ 满足:
$$ k \leq \left(\frac{R}{\gamma}\right)^2 $$
4.2 证明
为了简化,将 $b$ 吸收到 $w$ 中:定义 $\hat{w} = (w^T, b)^T$,$\hat{x} = (x^T, 1)^T$,则 $w \cdot x + b = \hat{w} \cdot \hat{x}$。
证明思路:
令 $\hat{w}_k$ 是第 $k$ 次误分类后的扩展权值向量(初始 $\hat{w}_0 = 0$)。
下界:每次更新使 $\hat{w}k$ 向 $\hat{w}{\text{opt}}$ 的投影至少增加一个常数:
$$ \hat{w}_k \cdot \hat{w}_{\text{opt}} \geq k \eta \gamma $$
因为:当对 $(x_i, y_i)$ 进行第 $k$ 次误分类更新时,
$$
\begin{aligned}
\hat{w}_k \cdot \hat{w}_{\text{opt}} &= (\hat{w}_{k-1} + \eta y_i \hat{x}_i) \cdot \hat{w}_{\text{opt}} \\
&= \hat{w}_{k-1} \cdot \hat{w}_{\text{opt}} + \eta y_i (\hat{x}_i \cdot \hat{w}_{\text{opt}}) \\
&\geq \hat{w}_{k-1} \cdot \hat{w}_{\text{opt}} + \eta \gamma
\end{aligned}
$$
由递推,得 $\hat{w}k \cdot \hat{w}{\text{opt}} \geq k \eta \gamma$。
上界:第 $k$ 次误分类更新时,$|\hat{w}_k|^2$ 的增长有界:
$$ \|\hat{w}_k\|^2 \leq k \eta^2 R^2 $$
因为:
$$
\begin{aligned}
\|\hat{w}_k\|^2 &= \|\hat{w}_{k-1} + \eta y_i \hat{x}_i\|^2 \\
&= \|\hat{w}_{k-1}\|^2 + 2\eta y_i \hat{w}_{k-1} \cdot \hat{x}_i + \eta^2 \|\hat{x}_i\|^2 \\
&\leq \|\hat{w}_{k-1}\|^2 + \eta^2 R^2
\end{aligned}
$$
(注意:$2\eta y_i \hat{w}_{k-1} \cdot \hat{x}i \leq 0$ 因为 $(x_i, y_i)$ 在 $\hat{w}{k-1}$ 下是误分类的)
结合上下界:
由 Cauchy-Schwarz 不等式:
$$
k \eta \gamma \leq \hat{w}_k \cdot \hat{w}_{\text{opt}} \leq \|\hat{w}_k\| \|\hat{w}_{\text{opt}}\| \leq \sqrt{k} \eta R \cdot 1
$$
从而:
$$
k \gamma \leq \sqrt{k} R \implies \sqrt{k} \leq \frac{R}{\gamma} \implies k \leq \left(\frac{R}{\gamma}\right)^2
$$
证毕。
4.3 定理的意义
- 有限步收敛:当数据线性可分时,感知机算法一定在有限步内收敛
- 误分类次数的上界:与初始值和学习率 $\eta$ 无关($\eta$ 被约掉了)
- 间隔的重要性:$\gamma$ 越大(线性可分越”容易”),收敛越快
- **数据的”难度”**:$R/\gamma$ 刻画了问题的难度——间隔越小或数据越分散,需要的迭代次数越多
五、感知机的对偶形式
5.1 对偶形式的动机
从原始形式的更新规则可以看出,最终的 $w$ 和 $b$ 可以表示为训练样本的线性组合:
$$
w = \sum_{i=1}^{N} \alpha_i y_i x_i
$$
$$
b = \sum_{i=1}^{N} \alpha_i y_i
$$
其中 $\alpha_i = n_i \eta$,$n_i$ 是样本 $i$ 在训练过程中被误分类的次数。
这个形式的优势在于:训练样本仅以内积形式出现,为核技巧的应用打开了大门。
5.2 对偶形式算法
算法:感知机学习算法的对偶形式
输入:训练集 T,学习率 η ∈ (0, 1] |
5.3 Gram 矩阵
在对偶形式中,训练样本之间的内积被反复使用。我们可以预先计算好Gram 矩阵来加速:
$$ G = [x_i \cdot x_j]_{N \times N} $$
Gram 矩阵存储了所有训练样本对之间的内积,是一个 $N \times N$ 的对称矩阵。
5.4 对偶形式的 Python 实现
class PerceptronDual: |
六、核感知机
当数据不是线性可分的时候,标准的感知机永远无法收敛。一个解决方案是使用核技巧(kernel trick)将数据映射到高维空间。
6.1 核函数
用核函数 $K(x, z) = \phi(x) \cdot \phi(z)$ 替换 Gram 矩阵中的内积,而不需要显式地计算映射 $\phi$。
常用的核函数:
| 核函数 | 表达式 | 参数 |
|---|---|---|
| 线性核 | $K(x, z) = x \cdot z$ | 无 |
| 多项式核 | $K(x, z) = (x \cdot z + c)^d$ | $c \geq 0, d \geq 1$ |
| 高斯核(RBF) | $K(x, z) = \exp(-\gamma|x-z|^2)$ | $\gamma > 0$ |
| Sigmoid 核 | $K(x, z) = \tanh(\alpha x \cdot z + \beta)$ | $\alpha, \beta$ |
6.2 核感知机实现
class KernelPerceptron: |
七、XOR 问题与感知机的局限
7.1 XOR 问题
1969 年,Minsky 和 Papert 在《Perceptrons》一书中证明了单层感知机无法解决 XOR(异或)问题,这一结论直接导致了神经网络研究的第一次”寒冬”。
XOR 的真值表:
| $x_1$ | $x_2$ | XOR 输出 | 类别 |
|---|---|---|---|
| 0 | 0 | 0 | -1 |
| 0 | 1 | 1 | +1 |
| 1 | 0 | 1 | +1 |
| 1 | 1 | 0 | -1 |
在二维平面上,这 4 个点是线性不可分的——不存在一条直线能将两类分开。这个简单的反例揭示了感知机根本性的局限。
7.2 解决方案
多层感知机(MLP):XOR 可以通过两层感知机解决:
- 第一层:$h_1 = x_1 \text{ NAND } x_2$,$h_2 = x_1 \text{ OR } x_2$
- 第二层:$y = h_1 \text{ AND } h_2$
这等价于 XOR 的布尔分解:$x_1 \oplus x_2 = (x_1 \text{ NAND } x_2) \text{ AND } (x_1 \text{ OR } x_2)$
核方法:将 $(x_1, x_2)$ 映射到高维特征空间,如 $\phi(x_1, x_2) = (x_1, x_2, x_1 x_2)$,则 XOR 问题在这个三维空间中变得线性可分。
八、从感知机到现代神经网络
| 年代 | 里程碑 | 作者 | 意义 |
|---|---|---|---|
| 1958 | 感知机 | Rosenblatt | 第一个可学习的神经网络 |
| 1969 | 《Perceptrons》 | Minsky & Papert | 揭示单层感知机的局限 |
| 1986 | 反向传播 | Rumelhart, Hinton, et al. | 训练多层网络成为可能 |
| 1995 | SVM | Vapnik | 核方法的兴起,替代神经网络 |
| 2006 | 深度信念网络 | Hinton et al. | 深度学习复兴 |
| 2012 | AlexNet | Krizhevsky et al. | CNN 在 ImageNet 上的突破 |
感知机作为神经网络的种子,其核心思想——加权和、阈值激活、误差驱动的权重更新——至今仍然是所有神经网络的基础。理解感知机,就是在理解深度学习的”祖先”。
九、算法原理回顾
感知机算法原理:
- 对于每一个输入,乘以它的权重值;
- 把所有加权的输入相加
- 通过求和函数求得的和计算感知机的输出
十、面试高频问题
Q1:感知机的损失函数为什么要忽略 $\frac{1}{|w|}$?
两个原因:
- $\frac{1}{|w|}$ 不影响误分类点的集合(当 $y_i(w \cdot x_i + b) < 0$ 时,除以任何正数还是 < 0)
- 去掉 $\frac{1}{|w|}$ 后损失函数是 $w, b$ 的线性函数(实际上是分段线性的),梯度简洁
注意这导致了一个副作用:感知机最小化的不是”误分类点到超平面的几何距离之和”,而是”函数距离之和”。这两个量不一定等价,但在算法收敛的意义上是等效的。
Q2:原始形式和对偶形式有什么区别?什么时候用哪一个?
| 方面 | 原始形式 | 对偶形式 |
|---|---|---|
| 参数量 | $n$ ($w$) + 1 ($b$) | $N$ ($\alpha$) + 1 ($b$) |
| 计算模式 | 每次更新计算内积 $w \cdot x$ | 查 Gram 矩阵 |
| 适合场景 | $n \ll N$(特征少样本多) | $n \gg N$(特征多样本少) |
| 可核化 | 不直接 | 直接(替换 Gram 矩阵为核矩阵) |
实际中,如果 $N$ 很大(百万样本),对偶形式因为要存储 $N \times N$ 的 Gram 矩阵而变得不可行。对偶形式在样本数适中但特征维数极高(如文本数据)时很有用。
Q3:Novikoff 定理中 $\gamma$ 和 $R$ 的几何含义是什么?
- $\gamma$ 是所有样本到最优超平面的最小几何间隔。$\gamma$ 越大,数据集线性可分的”程度”越好,分类越容易。
- $R$ 是所有样本的最大范数(即所有样本到原点的最远距离)。$R$ 越大,数据分布越分散。
因此,$R/\gamma$ 刻画了问题的”条件数”——数据越分散($R$ 大)且可分间隔越小($\gamma$ 小),算法需要越多次迭代。这与数值分析中条件数的概念类似。
Q4:感知机与逻辑回归的区别是什么?
| 方面 | 感知机 | 逻辑回归 |
|---|---|---|
| 激活函数 | $\text{sign}(w \cdot x)$ | $\sigma(w \cdot x) = \frac{1}{1+e^{-w \cdot x}}$ |
| 损失函数 | Hinge loss 的简化版 | 交叉熵(log loss) |
| 输出 | 硬分类 ${\pm 1}$ | 概率 $[0, 1]$ |
| 数据要求 | 必须线性可分 | 不需要线性可分 |
| 收敛保证 | Novikoff 定理(线性可分下) | 梯度下降收敛 |
| 对离群点 | 非常敏感 | 相对鲁棒 |
Q5:感知机神经网络和现代深度网络在训练上的核心区别是什么?
三个关键区别:
- 激活函数:感知机用阶跃函数(step function),不可导;现代网络用 sigmoid、ReLU、GELU 等可导函数
- 训练算法:感知机用朴素 SGD(误差驱动的权重更新),层级之间没有梯度传递;现代网络用反向传播(backpropagation)逐层传递梯度
- 深度:单层 vs 数百上千层;深度的增加使得网络能学习层次化的特征表示
然而,感知机的核心思想(加权和 -> 非线性 -> 输出)仍然是所有深度网络的基础构件。
十一、总结
感知机是机器学习历史上的一座里程碑,它是神经网络的起源,也是统计学习理论发展的催化剂。虽然单层感知机只能解决线性可分问题(XOR 就是其”阿克琉斯之踵”),但它的思想——用简单的计算单元组合成复杂的决策系统——直接孕育了多层感知机和现代深度学习。
本文从感知机的直观引入出发,系统讨论了其数学模型、损失函数推导、SGD 优化算法、Novikoff 收敛定理、对偶形式以及核感知机。理解感知机不仅是学习《统计学习方法》的要求,更是理解所有基于梯度优化的学习算法的起点。
在下一章中,我们将继续探索线性分类器家族中更强大的成员——支持向量机(SVM),看它如何优雅地解决感知机”随缘分类”的问题,通过最大化分类间隔来获得更好的泛化能力。
参考文献:
- Rosenblatt, F. (1958). The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386-408.
- Novikoff, A. B. (1962). On convergence proofs for perceptrons. Symposium on the Mathematical Theory of Automata.
- Minsky, M., & Papert, S. (1969). Perceptrons: An Introduction to Computational Geometry.
- 李航. (2019). 《统计学习方法》(第2版). 第2章.
- Freund, Y., & Schapire, R. E. (1999). Large margin classification using the perceptron algorithm. Machine Learning, 37(3), 277-296.



