最近写论文笔记是各种疯(捉)狂(襟)百(见)度(肘)啊,对于自身的技术能力个人感觉实在是”太下饭”了。算算从五月份自学到现在也半年有余,买过书上过课,从最开始接触 Andrew Ng 的 Coursera上的机器学习课程到入手第一本西瓜书之后,又陆陆续续买了《机器学习实战》、《统计学习方法(第2版)》、《百面机器学习》等等,其实我的想法是很简单,跟着书后面死磕,总会培养出感情,无奈这几个月非但没看得到进步,反而越发觉得这门技术并非单单凭兴趣就能攻克的,它所需要的知识脉络是全面的,容不得一丝侥幸,因此既然这样,干脆来个二次入门。再加上临近年末也需要个人总结一下这一年的得与失,是时候给自己立个FLAG。
这次死磕系列结合《统计学习方法》,这本书涵盖了机器学习领域涉及到的各种核心技术研究,包括自然语言处理、信息检索、文本数据挖掘等。我也会尝试融合西瓜书一起,从零开始,做到手推算法重理解,尽量直观展示备注说明,并在每章最后附上经典面试题,或者是一个案例实战(数据竞赛题之类),以期可以系统性的掌握一套方法论应对未来数据之战。
系列目录如下
继《统计学习方法》一书之后,接下来着手的是有着”AI圣经”之称的《模式识别和机器学习》,业界普遍称其为PRML,相信任何一个搞机器学习、深度学习的人都应该听说过甚至看过,它共有14章节的内容,且每一章都是干货满满。整体目录如下:
系列目录如下
第一章 介绍
第二章 概率分布
第三章 线性回归模型
第四章 线性分类模型
第五章 神经网络
第六章 内核方法:双重表征、构造内核、径向基函数网络、高斯过程
第七章 稀疏内核机器:最大边距分类器、相关向量机
第八章 图形模型:贝叶斯网络、条件独立、马尔科夫随机场、图形模型中的推理
第九章 混合模型和EM:K-means聚类、高斯混合、EM算法
第十章 近似推断
第十一章 采样方法
第十二章 连续潜在变量
第十三章 顺序数据
第十四章 组合模型
更令人兴奋地是,目前PRML已经被微软”开源”啦
传送门
附上学习路线图
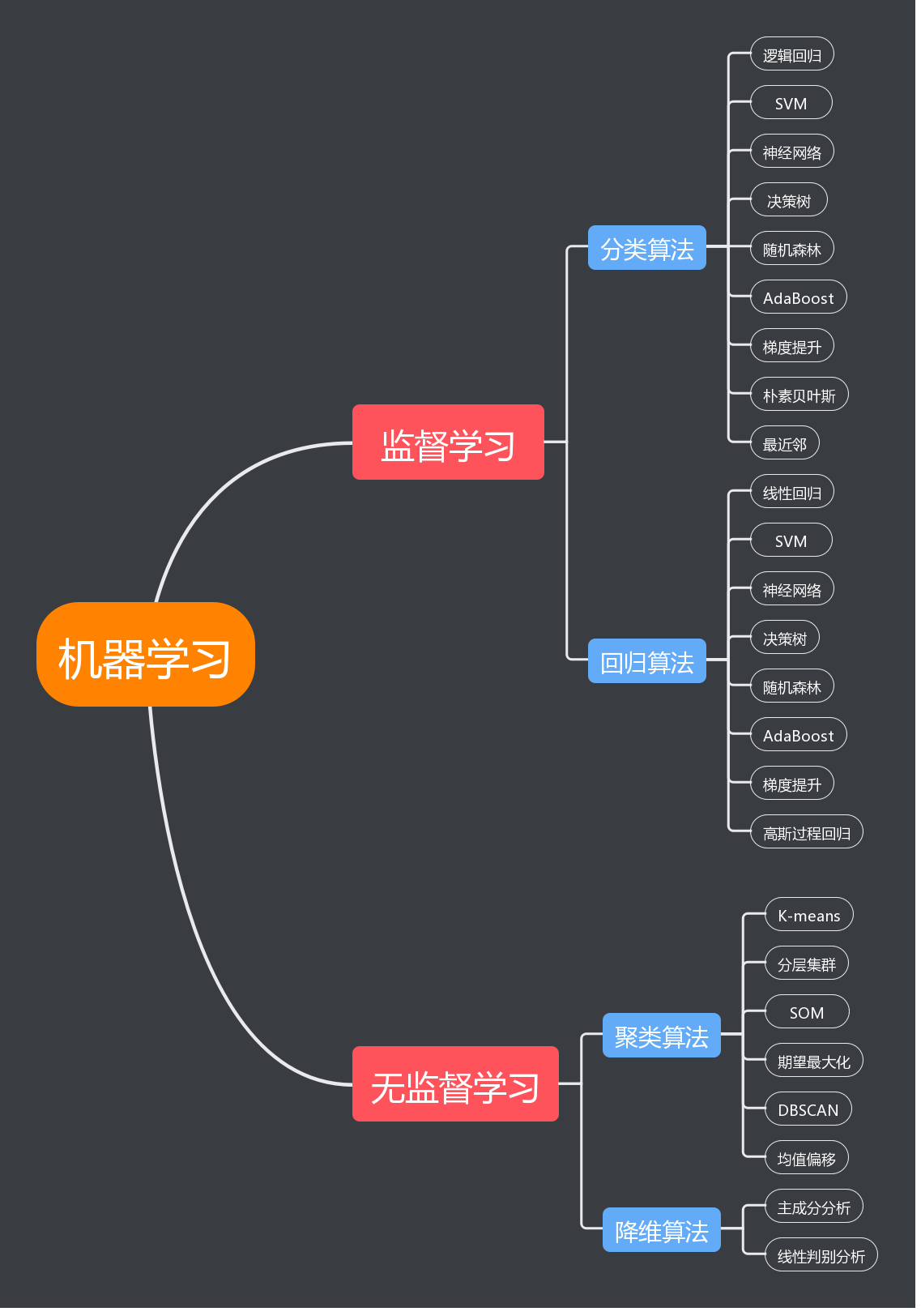
一、回望 2019:一个 ML 新手的自白
半年时间,从对机器学习只有模糊概念到能动手推导 SVM 的 KKT 条件、能读懂 LDA 的 Gibbs 采样,回头看来,这段自学之路走得磕磕绊绊但收获满满。整理一下这一路的经验和踩过的坑,也许能帮到同样在自学路上挣扎的同学。
1.1 踩过的坑
坑一:眼高手低,只看不写。
最初看 Andrew Ng 的课程时,觉得”这个简单啊,梯度下降不就是求导后下坡吗”,于是一路刷完视频,连课后作业都没做。结果一遇到真实数据就傻眼——学习率设多少?特征要不要归一化?训练不收敛怎么办?这些问题在视频里没有标准答案,只有亲自写代码才会遇到。代码一行不写,等于没学。
坑二:贪多嚼不烂,同时看多本书。
西瓜书、统计学习方法、PRML、花书、深度学习……每一本都翻了几十页,每一本都没读完。东一榔头西一棒槌,知识不成体系。后来悟到一个道理:在同一阶段专心啃完一本书,胜过同时读十本书的前两章。
坑三:忽视数学基础,急于上模型。
一开始看到 SVM 的对偶问题就跳过去,觉得”反正 sklearn 里有现成的”。后来发现在面试中,面试官最喜欢刨根问底——“为什么用对偶?核函数是怎么引入的?KKT 条件在这个问题里扮演什么角色?”这些问题的答案不在一行 fit() 调用里,而在凸优化和泛函分析的理论中。
坑四:只有输入没有输出,学了就忘。
看了再多的推导,如果不自己写出来、讲出来,三天就忘了。后来养成了一个习惯:每学完一个算法,就写一篇博客,包含手推公式、数值例子和代码。虽然费时间,但写完之后这个算法基本就”焊”在脑子里了。费曼学习法的核心就是:以教促学。
1.2 一点体会
机器学习的学习曲线不是线性的——它更像台阶式的。开始很长一段时间你感觉自己原地踏步,然后某一天突然”通”了,之前分散的知识点串联起来了。这个顿悟时刻通常发生在你把某个算法从头到尾完整推导一遍之后。
所以,耐心。给自己时间。
二、机器学习知识体系全景图
经过半年的学习,我逐渐梳理出一张 ML 知识地图。它将机器学习需要掌握的内容分为四大板块,每个板块有其核心主题和关键知识点。
2.1 板块一:数学基础
| 主题 | 核心内容 | 重要程度 | 推荐资源 |
|---|---|---|---|
| 线性代数 | 矩阵运算、特征值与特征向量、SVD、矩阵微积分 | ★★★★★ | Gilbert Strang MIT 18.06 |
| 概率论 | 条件概率、贝叶斯定理、常见分布族、大数定律 | ★★★★★ | 《概率论与数理统计》浙大版 |
| 信息论 | 熵、交叉熵、KL 散度、互信息 | ★★★★ | Cover & Thomas 前几章 |
| 最优化 | 梯度下降、拉格朗日对偶、KKT 条件、凸优化基础 | ★★★★★ | Boyd & Vandenberghe(选读) |
| 统计推断 | 极大似然、贝叶斯推断、假设检验 | ★★★★ | Casella & Berger |
2.2 板块二:经典机器学习算法
按”是否适用于 80% 的问题”排序:
| 优先级 | 算法 | 核心概念 | 为什么重要 |
|---|---|---|---|
| P0 | 线性回归 / 逻辑回归 | 线性模型、梯度下降、正则化 | 所有模型的基础,面试必考 |
| P0 | 决策树 / 随机森林 / GBDT / XGBoost | 树模型、集成学习 | 竞赛利器,工业界最常用 |
| P0 | SVM | 最大间隔、对偶、核技巧 | 理论深度的试金石 |
| P1 | 朴素贝叶斯 | 贝叶斯定理、条件独立 | 文本分类、简单但有效 |
| P1 | k-NN | 距离度量、懒惰学习 | 理解距离与相似度 |
| P1 | K-means / GMM / DBSCAN | 聚类、密度估计、EM 算法 | 无监督学习的基石 |
| P1 | PCA / LDA | 降维、特征分解 | 数据预处理和高维可视化 |
| P2 | EM 算法 | 隐变量、Jensen 不等式 | 理解更复杂模型的基础 |
| P2 | HMM / CRF | 序列模型、动态规划 | NLP 和时序模型 |
| P2 | PageRank / LSA / LDA | 图算法、主题模型 | 理解机器学习的广度 |
2.3 板块三:深度学习
| 主题 | 核心内容 |
|---|---|
| 前馈网络 | MLP、反向传播、激活函数、初始化、归一化 |
| CNN | 卷积、池化、经典架构(ResNet, Inception, MobileNet) |
| RNN / LSTM / GRU | 序列建模、门控机制、Attention |
| Transformer | Self-Attention、Multi-Head Attention、Positional Encoding |
| 生成模型 | VAE、GAN、扩散模型基础 |
| 训练技巧 | 学习率调度、正则化(Dropout, BN)、迁移学习 |
2.4 板块四:工程与实践
| 主题 | 核心内容 |
|---|---|
| 特征工程 | 特征构造、选择、编码、时间特征、文本特征 |
| 模型评估 | 交叉验证、AUC-ROC、混淆矩阵、偏差-方差分解 |
| 调参与 AutoML | 网格搜索、贝叶斯优化、Optuna |
| 工程部署 | Flask/FastAPI 部署、TensorRT、ONNX、模型量化 |
| 大数据工具 | Spark MLlib、Ray、Dask |
| MLOps | 实验追踪、模型版本管理、CI/CD for ML |
三、四阶段学习路线
基于以上知识体系,我规划了一个四阶段学习路线。
阶段一:入门(1-2 个月)
目标:建立对机器学习的整体认知,能独立完成端到端的 ML 项目。
学习内容:
- Andrew Ng《Machine Learning》Coursera 课程(完成所有编程作业)
- 用 sklearn 跑通 iris、titanic、boston housing 等经典数据集
- 学习 pandas、numpy、matplotlib 基础
检验标准:能在 Kaggle 上独立完成 Titanic 和 House Prices 两个入门赛,提交并看懂 leaderboard。
阶段二:理论深化(3-5 个月)
目标:深入理解经典 ML 算法的数学原理,能手动推导核心公式。
学习内容:
- 精读《统计学习方法》(李航)+ 《机器学习》(周志华,西瓜书)
- 每个算法完成:手推公式 + 从零实现 + 博客总结
- 补充线性代数和概率论的知识盲区
检验标准:李航《统计学习方法》中每一个算法都能:
- 不看书写出数学推导
- 不用 sklearn 实现一遍
- 讲清楚它为什么有效、什么时候会失效
阶段三:实战与拓展(3-4 个月)
目标:将在 Kaggle/天池竞赛中锻炼实战能力,拓宽算法视野。
学习内容:
- 参加 3-5 个 Kaggle 竞赛(至少一个拿银牌)
- 深入学习 GBDT/XGBoost/LightGBM/CatBoost
- 学习特征工程的系统方法论
- PRML 选读(重点章节:3-5, 8-9, 11-12)
检验标准:Kaggle 至少一枚银牌;能总结出自己的竞赛方法论。
阶段四:专业化(持续进行)
目标:选择一个方向深挖,建立领域专长。
可选项:
- NLP 方向:CS224n + Transformers + BERT/GPT 家族
- CV 方向:CS231n + 目标检测 + 图像分割
- 推荐系统:协同过滤 + 深度学习推荐 + 实时推荐架构
- 强化学习:MDP + Q-Learning + Policy Gradient + PPO
四、推荐书单与阅读顺序
基于半年踩坑经验,我推荐以下阅读顺序。
4.1 入门必读
| 序号 | 书名 | 理由 | 难度 |
|---|---|---|---|
| 1 | 《机器学习》(周志华,西瓜书) | 中文最佳入门,覆盖面广 | ★★★ |
| 2 | 《统计学习方法》(李航) | 算法推导最详尽,面试必备 | ★★★★ |
| 3 | 《机器学习实战》 | 代码驱动,建立直觉 | ★★ |
4.2 进阶必读
| 序号 | 书名 | 理由 | 难度 |
|---|---|---|---|
| 4 | 《Pattern Recognition and Machine Learning》(Bishop) | 贝叶斯视角,理论深厚 | ★★★★★ |
| 5 | 《The Elements of Statistical Learning》(ESL) | 统计学习圣经 | ★★★★★ |
| 6 | 《Deep Learning》(花书,Goodfellow 等) | 深度学习理论奠基之作 | ★★★★★ |
4.3 实战与专题
| 书名 | 主题 | 适合阶段 |
|---|---|---|
| 《百面机器学习》 | 面试题解 | 阶段二/三 |
| 《Approaching (Almost) Any ML Problem》 | Kaggle 实战 | 阶段三 |
| 《Feature Engineering for ML》 | 特征工程 | 阶段三 |
| 《Designing Machine Learning Systems》 | ML 系统设计 | 阶段四 |
4.4 阅读建议
- 不要跳跃:先读完西瓜书,再读李航《统计学习方法》,再读 PRML/ESL。每本书都有自己的体系,混读只会一片混乱。
- 交叉阅读:遇到某个概念看不懂,不要死磕。换另一本书看同一章节,不同作者的表述常常能互相补充。
- 以代码检验理解:每读一章理论,就找相应的数据集写代码验证。
- 做好笔记:建立自己的 ML 知识库(Notion/博客均可),方便随时查阅和面试前复习。
五、2019 年机器学习领域回顾
站在 2019 年末回望,这一年 ML 领域发生了许多里程碑式的事件。
5.1 自然语言处理:BERT 之年
2018 年底 BERT 发布,2019 年是 BERT 全面统治的一年。从 GLUE 到 SQuAD,BERT 及其变体(RoBERTa, ALBERT, DistilBERT, XLNet)刷新了几乎所有 NLP 基准。
关键趋势:
- 预训练 + 微调 成为 NLP 的标配范式
- 模型越做越大:从 BERT-base(110M 参数)到 GPT-2(1.5B 参数)
- 出现了专注于高效推理的轻量模型(DistilBERT, TinyBERT)
5.2 计算机视觉:EfficientNet 和自监督学习
- EfficientNet 用神经架构搜索(NAS)找到了一族在精度和效率之间平衡最佳的模型
- 自监督学习(MoCo, SimCLR)开始崭露头角——不用标签也能学出好的视觉表示
- StyleGAN 和 StyleGAN2 将图像生成的质量推到了以假乱真的新高度
5.3 强化学习:AlphaStar 和 OpenAI Five
- DeepMind 的 AlphaStar 在《星际争霸II》中击败了 99.8% 的人类玩家
- OpenAI Five 在 Dota 2 中击败了世界冠军 OG 战队
- 这些里程碑展示了 RL 在不完全信息、长期规划问题上的潜力
5.4 框架生态:PyTorch 崛起,TensorFlow 2.0 发布
- PyTorch 凭借动态图和 Pythonic 的 API 在学术界份额大幅增长
- TensorFlow 2.0 转向 eager execution 默认模式,并集成了 Keras
- 两大框架的竞争推动了整个生态的成熟
5.5 值得关注的 SOTA 论文(2019)
| 论文 | 领域 | 贡献 |
|---|---|---|
| BERT | NLP | Transformer 双向预训练 |
| EfficientNet | CV | NAS + 复合缩放 |
| MoCo | CV | 动量对比自监督学习 |
| XLNet | NLP | 排列语言模型 |
| StyleGAN2 | CV | 高质量图像生成 |
| GPT-2 | NLP | 大规模语言模型的 zero-shot 能力 |
六、机器学习面试准备路线图
打算找 ML 相关工作的同学,面试准备可以从以下几个方面着手。
6.1 算法理论(必须能手推)
面试官最喜欢让你在白板上推导的 10 个知识点:
- 逻辑回归:损失函数推导、梯度计算、为什么用交叉熵而不用 MSE
- SVM:硬间隔/软间隔的推导、对偶问题、KKT 条件、为什么引入核函数
- 决策树:信息增益、基尼指数、剪枝策略
- GBDT/XGBoost:梯度提升的原理、XGBoost 与 GBDT 的区别、二阶泰勒展开
- EM 算法:Jensen 不等式、Q 函数、GMM 推导
- PCA:两种等价推导、特征分解与 SVD
- L1 vs L2 正则化:几何解释、为什么 L1 产生稀疏解
- 偏差-方差分解:公式推导、Bias-Variance Tradeoff
- 梯度消失/爆炸:原因、解决方法(BN, 残差连接)
- Batch Normalization:训练与推理的区别、为什么有效
6.2 编程实现
以下模型必须能从零写出来(只用 numpy):
- 线性回归(含梯度下降)
- 逻辑回归(含 SGD)
- k-means
- 决策树(CART)
- 多层感知机(含反向传播)
- 至少一种 boosting(AdaBoost 或简单 GBDT)
6.3 场景题
常见的 ML 系统设计题:
- “设计一个推荐系统”
- “如何检测信用卡欺诈?”
- “如何做广告点击率预估?”
- “设计一个文本分类系统”
- “如何应对样本不平衡问题?”
回答框架:数据 -> 特征 -> 模型 -> 评估 -> 上线 -> 监控
6.4 项目经历
- 至少 1-2 个完整的 ML 项目(Kaggle 竞赛或实际业务项目)
- 能够讲清楚:问题的业务背景、数据特点、为什么选这个模型、评估指标的选择、遇到了什么问题、怎么解决的
七、FLAG for 2020
借着年终总结的机会,立下 2020 年的学习 Flag:
- 完成【统计学习方法死磕系列】全部文章(本篇正是起点)
- 完成 PRML 重点章节的精读笔记(至少第 3, 4, 6, 8, 9, 11, 12 章)
- Kaggle 拿至少一块银牌
- LeetCode 刷 100+ 题(ML 工程师同样需要 coding 基本功)
- 写 50 篇博客(以输出倒逼输入)
- 系统学习推荐系统,做一个端到端的推荐项目
flag 已经立在这里了,明年的这个时候再来复盘。希望到时候能对自己说一句:你做到了。
八、给同样在自学 ML 的同学的一封信
如果你也在自学机器学习,以下几点是我用半年踩坑换来的经验,送给你:
打好数学基础再上模型。把线性代数中的特征值、矩阵分解、概率论中的贝叶斯定理和常见分布、最优化中的梯度下降搞懂,后面的路会好走很多。
理论和代码并重。不要只看视频不写代码,也不要只调 sklearn 不推导。每天分配固定比例的时间给理论和实践。
找同伴一起学。一个人自学太容易放弃。加入学习社群、组队打 Kaggle、在论坛上回答问题,这些都能帮你坚持下去。
承认学习的非线性。有时你觉得自己一点都没进步,但实际上你正在从”能调 API”到”能改模型”的质变点上。坚持住。
面试是你的阶段性检验。即使不急着找工作,也可以定期看看面试题。它们能告诉你业界真正看重什么、你的知识体系还缺什么。
不要被大牛的履历吓到。每个大牛都是从”连梯度下降都不懂”的起点走出来的。接纳自己的学习节奏。
学 ML 是一场马拉松,不是百米冲刺。2019 年我迈出了第一步,2020 年继续死磕。
与所有在路上的自学者共勉。
八点五、如何高效阅读 ML 论文
死磕书本固然重要,但机器学习是一个快速演进的领域,很多关键知识只存在于论文中。以下是我总结的论文阅读方法论。
论文阅读的三遍法
| 步骤 | 时间 | 做什么 | 目标 |
|---|---|---|---|
| 第一遍 | 5-10 分钟 | 读标题、摘要、introduction 最后一段、结论、所有图表 | 判断是否值得深读 |
| 第二遍 | 30-60 分钟 | 通读全文,跳过复杂证明,理解方法核心和实验设计 | 理解”做了什么、效果如何” |
| 第三遍 | 2-4 小时 | 精读,推敲每个公式,在脑海里”复现”算法 | 能给别人讲清楚 |
论文笔记模板
每读完一篇重要论文,用以下模板做笔记:
【论文信息】标题、作者、年份、会议/期刊 |
2019 年值得深读的论文推荐
除了上文提到的年度 SOTA 论文,以下论文的”方法论”价值极高,建议精读:
| 论文 | 为什么值得精读 |
|---|---|
| Attention Is All You Need (Vaswani et al., 2017) | Transformer 架构的开山之作,论文写作和论证堪称典范 |
| Deep Residual Learning (He et al., 2016) | 残差连接的 insight 和 ablation study 极为缜密 |
| Adam (Kingma & Ba, 2015) | 优化器设计的标杆论文,偏理论和偏实验的平衡极好 |
| Dropout (Srivastava et al., 2014) | 正则化方法的经典,写 regularization 论文的范本 |
| Batch Normalization (Ioffe & Szegedy, 2015) | 如何将一个 trick 做到极致、论证到无可反驳 |
论文与书本的关系
不要把论文和书本对立起来。书本给你体系化的知识骨架,论文给你前沿的血肉。建议的学习方式是:
- 先用书本(西瓜书/统计学习方法/PRML)建立对该领域的系统认知
- 在读的过程中,如果某个方法被频繁引用(如 BERT, ResNet, Adam),就去找原论文精读
- 精读时重点关注”为什么之前的方法不行”——这个动机往往比方法本身更有价值
- 读完论文后回到书本,看能否用书本中的理论框架解释论文的创新点
记住:读论文不是为了”知道 SOTA 是什么”,而是为了理解”为什么这样做能 work”。后者需要你同时站在理论和实践的交叉点上思考。
九、面试高频问题(关于学习方法)
Q1:自学 ML 应该先看哪本书?西瓜书还是统计学习方法?
如果你数学基础较好:先看《统计学习方法》。它对单个算法的推导非常详尽,全书条理清晰,适合建立”推导习惯”。但它的缺点是不包含决策树和神经网络等内容。
如果你数学基础一般:先看《机器学习》(西瓜书)。它的覆盖面更广,包含了决策树、神经网络、聚类等,且每个算法都有直观解释。缺点是某些推导不够详尽。
我的建议:两本书交叉看。看完统计学习方法的感知机、k-NN、朴素贝叶斯后,翻翻西瓜书同章节做补充。然后回来看统计学习方法的决策树(西瓜书的第 4 章)。
Q2:需要把所有算法的数学推导都背下来吗?
不需要”背”,但需要”能推”。区别在于:背是机械记忆,推导是理解因果链条。面试官让你推 SVM 的对偶,他不是想看你能默写公式,而是想看你能不能讲清楚”为什么要引入对偶”——这个问题的答案是:为了引入核函数(对偶形式中数据只以内积出现)和减少变量数(当特征维数 > 样本数时)。
理解了”为什么”,推导自然水到渠成。
Q3:什么时候开始打 Kaggle 比较合适?
学完逻辑回归、决策树和随机森林后就可以开始了。不需要等学完所有理论。Kaggle 的入门赛(Titanic, House Prices)是极好的学习素材——它们能让你直观地感受到特征工程的重要性、不同模型的差异、以及交叉验证的必要性。
建议每学完一个模型就去找对应的 Kernel/Notebook 学习别人的思路。先模仿,后超越。
Q4:ML 工程师需要多深的工程能力?
取决于你的目标。如果是研究型岗位,能写干净的代码、会用 PyTorch/TensorFlow 就够了。如果是工程型岗位,除了 ML 知识外,你还需要:
- 熟练的数据处理能力(SQL, Spark)
- 基本的后端开发能力(能部署模型为 API)
- 了解 Docker、Kubernetes
- 了解模型优化(量化、剪枝、ONNX 导出)
- CI/CD for ML(MLOps)
Q5:如何保持长期自学的动力?
两个核心策略:
以项目驱动学习。不要纯粹为了”学完这本书”而学习。找到一个你想做的项目(比如”做一个能识别猫品种的 App”),为了完成它去学你需要的知识。有目标的学习比无目标的学习效率高得多。
建立反馈闭环。自学最大的敌人是不知道自己”学得对不对”。解决方式:写博客(读者反馈)、打 Kaggle(分数反馈)、参加面试(面试官反馈)。没有反馈的学习就像在黑暗中射箭,你永远不知道方向对不对。
Q6:数学基础不够好,怎么补?
这个问题几乎每个自学者都会问。我的建议是”用到什么学什么,以算法为纲”——不要试图先把所有数学学完再开始 ML,那样会遥遥无期。
具体操作:
线性代数:重点搞懂特征值/特征向量、矩阵分解(SVD、EVD)、矩阵微积分。Gilbert Strang 的 MIT 18.06 公开课的前 15 讲就够了。不需要一上来就学 Jordan 标准型或矩阵分析。
概率论:理解贝叶斯定理、条件概率、常见分布族(Gaussian, Bernoulli, Multinomial, Dirichlet, Beta, Gamma)的形式和共轭关系。浙大概率论教材 + 一个 cheat sheet 足矣。
最优化:先搞懂梯度下降(BGD, SGD, Mini-batch)、拉格朗日乘子法、KKT 条件的直观含义。Boyd 的凸优化是大部头,建议当参考书而非教材——遇到不懂的概念再查。
信息论:只需要理解熵、交叉熵、KL 散度的定义和它们之间的关系。Cover & Thomas 的书前两章就够了。
核心原则:不要脱离算法学数学。当你在推导 SVM 对偶问题时遇到了拉格朗日乘子法,这时去学最优化是最有效率的——你知道为什么要学、学了能解决什么问题。
Q7:工作了以后,如何保持持续学习的节奏?
这个问题非常现实。工作后的大块时间会明显减少,碎片化学习成为常态。以下策略对我有效:
固定时段:每天固定 1-2 小时(如早上 6:30-8:00 或晚上 9:00-10:30)用于学习,雷打不动。周末至少拿出半天做深度学习。
以项目定学习:不要为了学而学。定了要做一个推荐系统项目,然后为了完成它去学协同过滤、SVD、DNN for recommendation——有目标的学习效率远高于漫无目的的看书。
碎片时间读论文:通勤、排队等碎片时间用手机读论文的第一遍(abstract + conclusion + figures),标记需要精读的论文。大块时间再做第二遍、第三遍的精读和推导。
利用输出倒逼输入:给自己定下”每周写一篇博客”的目标。为了写一篇有质量的博客,你自然需要深入理解、查阅资料、验证代码。这个过程本身就是最高效的学习。
建立知识索引而非知识存储:不要试图把所有知识点都记在脑子里。建立”问题 -> 在哪能找到答案”的索引就够了。面试或项目需要时,你知道去哪里找。
记住:持续学习的敌人不是时间不够,是丧失动力。保持动力最好的方式就是不断看到自己”能做出以前做不出的东西”。
Q8:PRML 这本书到底怎么读?
PRML(Bishop, 2006)是 ML 领域公认的”圣经”之一,但 758 页的体量确实让人望而生畏。以下是我规划的精读策略:
优先章节(必须先读):第 1 章(介绍)、第 2 章(概率分布)、第 3 章(线性回归模型)。这三章建立了全书贝叶斯视角的基础语言。
核心章节(按需选读):第 4 章(线性分类模型,对比逻辑回归和 SVM)、第 6 章(核方法,理解高斯过程)、第 8 章(图模型,理解变量间的条件独立结构)、第 9 章(混合模型与 EM)、第 11-12 章(采样方法与连续潜变量,理解 MCMC 和 PCA)。
进阶章节(有充足时间再读):第 5 章(神经网络,内容偏旧但框架仍然有价值)、第 7 章(稀疏核机,RVM 如今用得少但方法论有价值)、第 10 章(近似推断,变分推断的早期论述)。
每章的习题:PRML 的习题非常出名地难,但也非常出色。建议至少做每章的前 5 道题。答案可以在网上找到(有非官方的解答集)。
阅读节奏建议:每周读一章(约 30-50 页),配合手推公式和代码实现。一本书读完大约需要 3-4 个月。
这篇写在 2019 尾巴上的文字,既是对过去的总结,也是对未来的期许。FLAG 已经立好,接下来的【统计学习方法死磕系列】系列文章,就是我在 2020 年践行的第一步。
Keep calm and keep learning.

